PAN World Model
Source:
- PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
It also has a demo website.
PAN World Model
PAN is a general, interactive, long-horizon world model.
- General: works across many real-world video domains.
- Interactive: state transitions are conditioned on actions (a_t).
- Long-horizon: can roll out many steps with limited drift.
Architecturally, PAN is a latent world model with visual encoder, decoder and a dynamics fucntion which is implemented by a pretrained QWen LLM.
Honestly, PAN’s idea is pretty simple, and the paper isn’t as famous as classics like DINO. I read it because one of the authors is a friend of my friend, and my friend recommended it :)
I'll quickly introduce its core formulation and then focus on three parts of the paper that I found interesting:
- How PAN integrates an LLM into world model
- How PAN extends the imagination horizon
- (The most important one) How PAN builds the dataset
Core formulation (GLP)
PAN presents its architecture under the name Generative Latent Prediction (GLP)—a standard encoder–dynamics–decoder setup with reconstruction supervision.
At time \(t\):
- observation: \(O_t\)
- action: \(a_t\)
- latent state: \(\hat{s}_t\)
Components: - Encoder:
\[ \hat{s}_t=h\left(o_t\right) \]
- Latent dynamics, or the transition function:
\[ \hat{s}_{t+1}=f\left(\hat{s}_t, a_t\right) \]
- Decoder:
\[ \hat{o}_{t+1}=g\left(\hat{s}_{t+1}\right) \]
Training loss:
\[ \mathcal{L}=\operatorname{disc}\left(\hat{o}_{t+1}, o_{t+1}\right) \] where \(\mathrm{disc}(\cdot, \cdot)\) is a flow matching loss.
Part 1: How PAN uses an LLM for world dynamics
PAN does not use an RNN, diffusion model, or a transformer trained from scratch for dynamics. Rather, it uses a pretrained Qwen2.5-VL model as the transition function. It predicts the next latent state instead of pixels. The state is represented as a fixed set of 256 continuous tokens,
Figure 1 illustrates the model inferrence process:
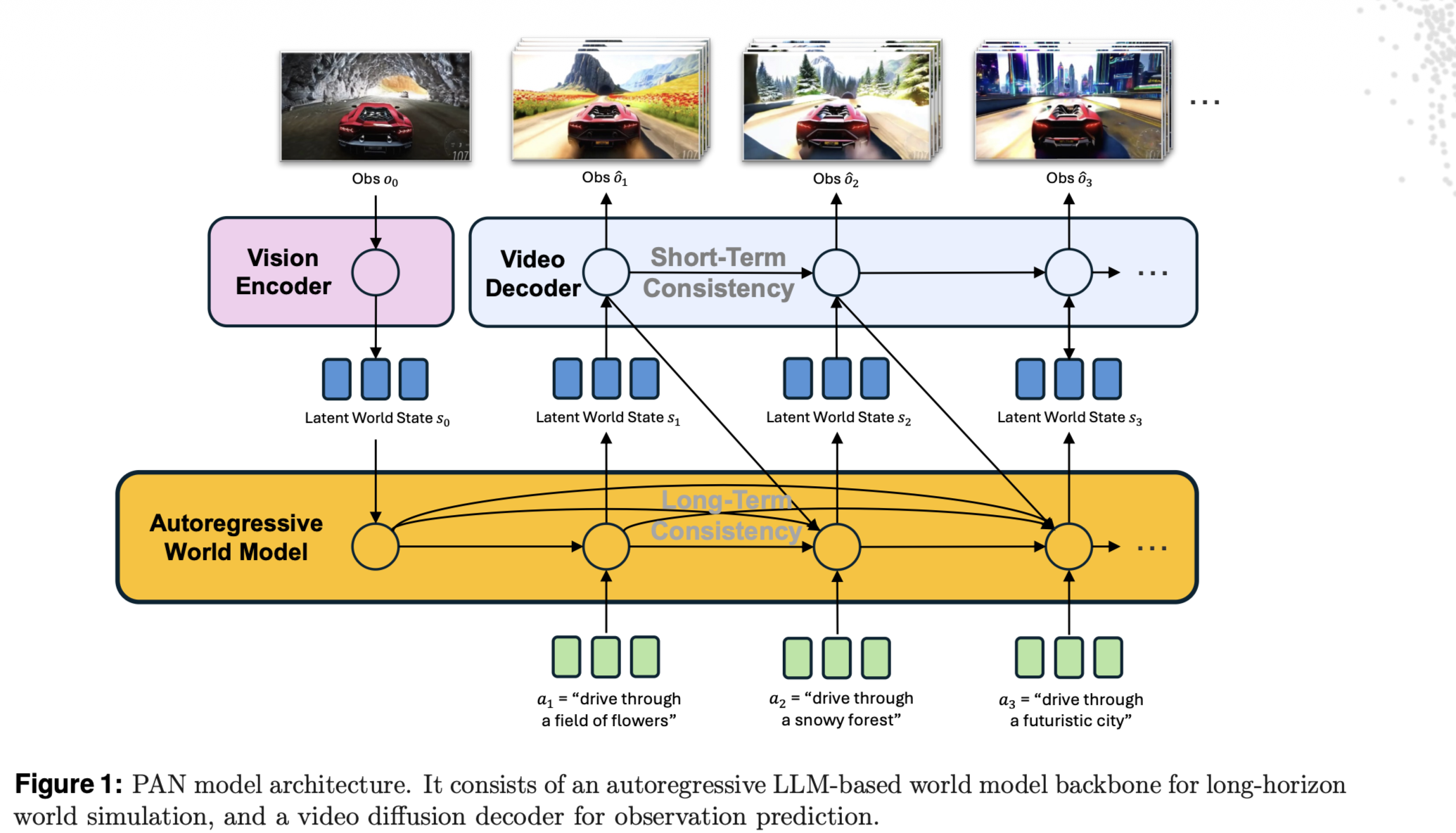
How inputs are formatted:
- They feed the model a multi-turn “chat” sequence.
- Each step alternates: (visual state) + (text action) → (predicted latent tokens).
- This matches the pretrained VLM dialogue format. (See §3.2.1.)
What context it uses:
- f conditions on the full history (s1, a1, …, st, at), not just (st, at). That's why in Figure 1 the autoregression process is noted to have "long-term" consistent. (See §3.2 and §5.)
Also, due to the dynamics being a LLM, PAN uses text actions.
Part 2: How PAN lengthens the prediction horizon
Lots of world models suffer from imagination horizon. PAN attacks this in its diffusion decoder. It basically involves starting from a pretrained VLM and adjusting the VLM with a Causal Swin-DPM architecture.
These content are all at §3.3 (Video Diffusion Decoder) in the paper and I'll skip them as they're a bit engineering. But I recommend you to read it if you want some inspriations of the horizon problem.
Part 3: Dataset and where the “action text” comes from
The paper writes the dataset as triples: \((o_t, a_t, o_{t+1})\).
The dataset is supposed to be very large and diverse as PAN is a large model and claims itself to generalize well.
Its collection process is described in §6 (Training Data), which involves:
- Collecting public videos and segment them into clips.
- Filtering the clips by some heuristics
- Dense re-captioning each clip.
The re-captioning part is the most import one as it's where action \(a_t\) is added and paired with observation \(o_t\).
(Fairly speaking, I think the most valuable component of this work is its dataset because the model architecture and training algorithm are all trivial.)
Although the author didn't discribe this part in deteil, we still know that:
- Each caption is expected to be detailed (dense) and describes dynamis of the video, instead of static backgrounds.
- Captions are generated bu some pretrained VLM.
The last thing worth mentioning about this paper is that it has a extensive evaluation (in §7 and §8) which involves both quantitive and qualititive analysis, and it even proposes to measure the model dynamis instead of simply the single frame reconstruction quality. I agree with this evaluation protocal as the dynamics of the wm is arguably the most important property of it but its measurement is largely ignored by most works.