Variance-Invariance-Covariance Regularization
Sources:
- VICReg 2022 paper
- VC Reg, a follow-up paper of VICReg
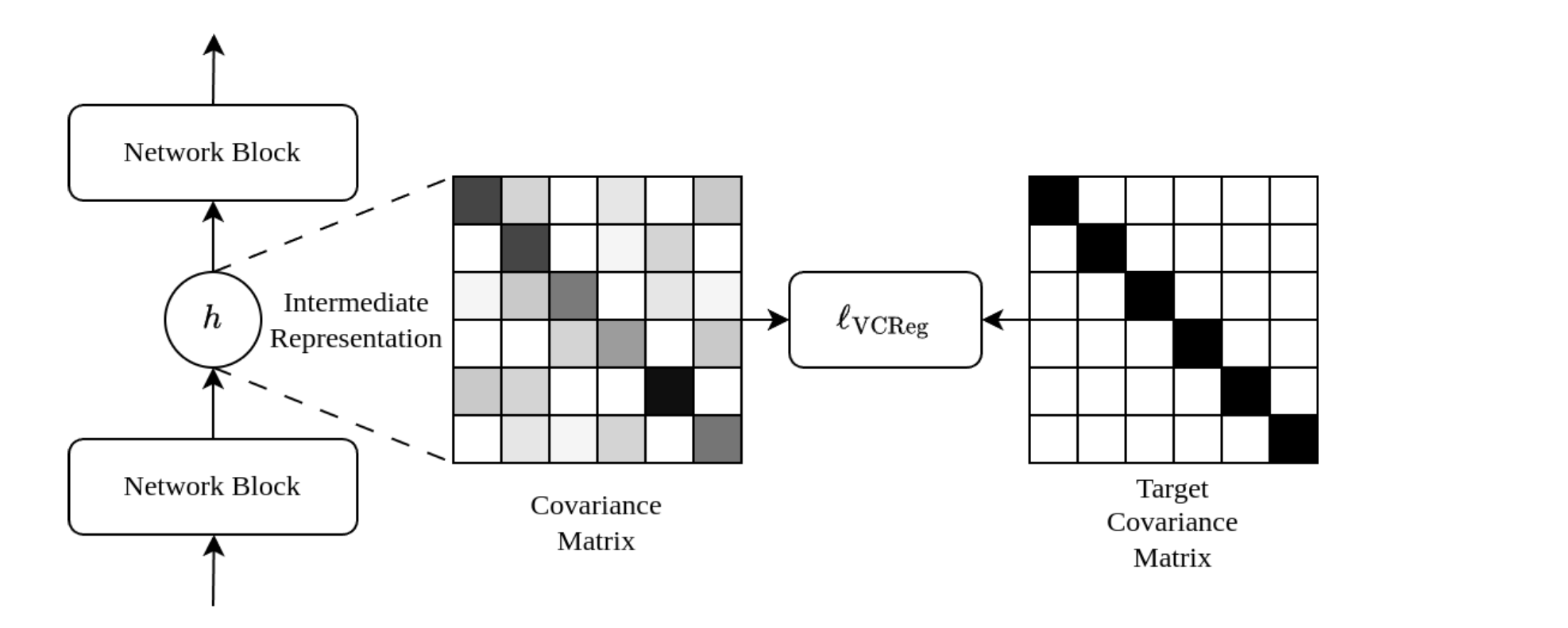
Image source: https://arxiv.org/pdf/2306.13292
# TODO: This note is flawed and I'll rewrite it in future.
Variance-Invariance-Covariance Regularization
Self-supervised learning methods aim to learn meaningful representations without relying on labels. VICReg (Variance-Invariance-Covariance Regularization) is one such method, which learns representations by optimizing three key objectives: maintaining variance, reducing covariance, and ensuring invariance between augmented views of the same input.
In this article, we focus solely on the core idea of VICReg—the design of its loss function—excluding discussions about network architectures and implementation details.
Notation
| Symbol | Type | Description |
|---|---|---|
| \(x_i\) | \(\mathbb{R}\) | The \(i\)-th original input in the batch |
| \(x_i^{\prime},x_i^{\prime\prime}\) | \(\mathbb{R}\) | Two augmented versions of the original input \(x_i\) |
| \(f_\theta(\cdot)\) | Function | Neural network parameterized by \(\theta\), used to generate embeddings |
| \(z_i^{\prime},z_i^{\prime\prime}\) | \(\mathbb{R}^d\) | Representations of \(x_i^{\prime}\) and \(x_i^{\prime\prime}\) generated by \(f_\theta\) |
| \(Z^{\prime},Z^{\prime\prime}\) | \(\mathbb{R}^{d \times n}\) | Batch embeddings for augmented inputs, where \(Z^{\prime},Z^{\prime\prime} \in \mathbb{R}^{d \times n}\) |
| \(z^{\prime j},z^{\prime\prime j}\) | \(\mathbb{R}^n\) | The \(j\)-th row of \(Z^{\prime}\) or \(Z^{\prime\prime}\), representing values for the \(j\)-th dimension across all samples |
| \(\operatorname{Cov}(Z^{\prime})\) | \(\mathbb{R}^{d \times d}\) | Variance-covariance matrix of \(Z^{\prime}\) |
| \(\operatorname{Var}(z^{\prime j})\) | \(\mathbb{R}\) | Variance of the \(j\)-th dimension across embeddings in \(Z^{\prime}\) |
| \(\gamma\) | \(\mathbb{R}\) | Threshold for variance regularization (e.g., \(\gamma = 1\)) |
| \(\ell(Z^{\prime},Z^{\prime\prime})\) | \(\mathbb{R}\) | Overall VICReg loss function |
| \(v(Z^{\prime}),c(Z^{\prime}),s(Z^{\prime},Z^{\prime\prime})\) | \(\mathbb{R}\) | Variance loss, covariance loss, and invariance loss, respectively |
| \(\mu,\nu,\lambda\) | \(\mathbb{R}\) | Hyperparameters controlling the weight of variance, covariance, and invariance terms |
Abbreviations
| Abbreviation | Description |
|---|---|
| VICReg | Variance-Invariance-Covariance Regularization |
| Cov | Covariance |
| Var | Variance |
| NN | Neural network |
Problem setting
We consider a batch of data \(\left\{x_1, \ldots, x_n\right\}\). For each sample \(x_i\), two augmented views \(x_i^{\prime}\) and \(x_i^{\prime \prime}\) are generated. These augmentations are passed through a neural network \(f_\theta(\cdot)\), producing embeddings:
\[ z_i^{\prime}=f_\theta\left(x_i^{\prime}\right) \quad \text { and } \quad z_i^{\prime \prime}=f_\theta\left(x_i^{\prime \prime}\right) \]
where \(z_i^{\prime}, z_i^{\prime \prime} \in \mathbb{R}^d\). The embeddings for the entire batch are represented as two matrices:
\[ Z^{\prime}=\left[z_1^{\prime}, z_2^{\prime}, \ldots, z_n^{\prime}\right] \quad \text { and } \quad Z^{\prime \prime}=\left[z_1^{\prime \prime}, z_2^{\prime \prime}, \ldots, z_n^{\prime \prime}\right] \]
where \(Z^{\prime}, Z^{\prime \prime} \in \mathbb{R}^{d \times n}\).
The variance-covariance matrix of \(Z^{\prime}\) is defined as:
\[ \operatorname{Cov}\left(Z^{\prime}\right)=\mathbb{E}\left[\left(Z^{\prime}-\mathbb{E}\left[Z^{\prime}\right]\right)\left(Z^{\prime}-\mathbb{E}\left[Z^{\prime}\right]\right)^T\right] \]
Expanding this:
\[ \operatorname{Cov}\left(Z^{\prime}\right)=\left[\begin{array}{ccc} \operatorname{Cov}\left(z_1^{\prime}, z_1^{\prime}\right) & \cdots & \operatorname{Cov}\left(z_1^{\prime}, z_n^{\prime}\right) \\ \vdots & \ddots & \vdots \\ \operatorname{Cov}\left(z_n^{\prime}, z_1^{\prime}\right) & \cdots & \operatorname{Cov}\left(z_n^{\prime}, z_n^{\prime}\right) \end{array}\right] \]
VICReg loss
VICReg optimizes three goals:
High Variance: Encourage \(\operatorname{Var}\left(z^{\prime j}\right)\) to prevent collapse, where all embeddings \(z_i^{\prime}\) become identical. For example, if all embeddings are mapped to the same vector \([1, 2, \ldots, d]\): \[ Z^{\prime}=\left[\begin{array}{cccc} 1 & 1 & \cdots & 1 \\ 2 & 2 & \cdots & 2 \\ \vdots & \vdots & \ddots & \vdots \\ d & d & \cdots & d \end{array}\right] \] In this case, each dimension \(z^{\prime j}\) (e.g., \(z^{\prime 1} = [1, 1, \ldots, 1]\)) has no variation, resulting in: \[ \operatorname{Var}\left(z^{\prime j}\right) = 0 \quad \forall j \] To prevent this, VICReg introduces the variance loss1: \[ \textcolor{salmon}{v\left(Z^{\prime}\right)}=\frac{1}{d} \sum_{j=1}^d \max \left(0, \gamma-\operatorname{Var}\left(z^{\prime j}\right)\right) \]
Low Covariance: Minimize off-diagonal elements of \(\operatorname{Cov}\left(Z^{\prime}\right)\). The covariance loss: \[ \textcolor{violet}{c\left(Z^{\prime}\right)}=\frac{1}{d} \sum_{i \neq j}\left[\operatorname{Cov}\left(Z^{\prime}\right)\right]_{i, j}^2 \] This reduces redundancy by minimizing overlap between dimensions.
Invariance: Ensure embeddings \(Z^{\prime}\) and \(Z^{\prime \prime}\) of the same input are similar. The invariance loss: \[ \textcolor{teal}{s\left(Z^{\prime}, Z^{\prime \prime}\right)}=\frac{1}{n} \sum_{i=1}^n\left\|z_i^{\prime}-z_i^{\prime \prime}\right\|_2^2 \] This loss term is where contrastive learning resides: pushing two positive embeddings closer.
The overall VICReg loss: \[ \ell\left(Z^{\prime}, Z^{\prime \prime}\right) = \textcolor{salmon}{\mu\left[v\left(Z^{\prime}\right)+v\left(Z^{\prime \prime}\right)\right]} + \textcolor{violet}{\nu\left[c\left(Z^{\prime}\right)+c\left(Z^{\prime \prime}\right)\right]} + \textcolor{teal}{\lambda s\left(Z^{\prime}, Z^{\prime \prime}\right)} \] where \(\lambda, \mu\) and \(\nu\) are hyperparameters controlling the importance of each term in the loss.
My comment
Invariance term is contrastive learning. Other two terms are heuristic tricks.
In the original paper, \(\operatorname{Var}\left(z^{\prime j}\right)\) is replaced by $ $, where \(\epsilon\) is a small constant for numerical stability. This is an engineering choice and does not affect the core idea. In this article, we use the simpler version for clarity and intuitiveness.↩︎