Vector Quantized Variational Autoencoders
Sources:
- VQ-VAE 2018 paper
- A compact explanation by Julius Ruseckas
Link: My VQ-VAE implementation on Github
Vector Quantized Variational Autoencoders
Notation
| Symbol | Type | Explanation |
|---|---|---|
| \(x, y, z\) | \(\in \mathbb{R}\) | Cartesian coordinates |
| \(u, v, w\) | \(\in \mathbb{R}\) | General curvilinear coordinates |
| \(r, \phi, z\) | \(\in \mathbb{R}\) | Cylindrical coordinates |
| \(R, \theta, \phi\) | \(\in \mathbb{R}\) | Spherical coordinates |
| \(\mathbf{r}\) | \(\in \mathbb{R}^3\) | Position vector |
| \(\hat{\mathbf{x}}, \hat{\mathbf{y}}, \hat{\mathbf{z}}\) | \(\in \mathbb{R}^3\) | Cartesian unit basis vectors |
| \(\hat{\mathbf{r}}, \hat{\boldsymbol{\phi}}, \hat{\mathbf{z}}\) | \(\in \mathbb{R}^3\) | Cylindrical unit basis vectors |
| \(\hat{\mathbf{R}}, \hat{\boldsymbol{\theta}}, \hat{\boldsymbol{\phi}}\) | \(\in \mathbb{R}^3\) | Spherical unit basis vectors |
| \(\mathbf{e}_u, \mathbf{e}_v, \mathbf{e}_w\) | \(\in \mathbb{R}^3\) | Base vectors in the transformed coordinate system |
| \(d\mathbf{l}\) | \(\in \mathbb{R}^3\) | Differential displacement vector |
| \(d\mathbf{l}_u, d\mathbf{l}_v, d\mathbf{l}_w\) | \(\in \mathbb{R}^3\) | Differential displacement vectors along each coordinate |
| \(d\mathbf{s}\) | \(\in \mathbb{R}^3\) | Differential area vector |
| \(d\mathbf{s}_u, d\mathbf{s}_v, d\mathbf{s}_w\) | \(\in \mathbb{R}^3\) | Differential area vectors along each coordinate |
| \(dV\) | \(\in \mathbb{R}\) | Differential volume element |
| \(J\) | \(\in \mathbb{R}^{3 \times 3}\) | Jacobian matrix of the coordinate transformation |
| \(\operatorname{det} J\) | \(\in \mathbb{R}\) | Determinant of the Jacobian matrix, used for volume scaling |
| \(\mathbf{e}_u \cdot (\mathbf{e}_v \times \mathbf{e}_w)\) | \(\in \mathbb{R}\) | Scalar triple product of base vectors, equal to \(\operatorname{det} J\) |
| \(\nabla\) | Operator | Gradient operator |
Introduction
This section is modified from the brilliant and compact introduction of VQ-VAE from Finite Scalar Quantization: VQ-VAE Made Simple
Vector quantization (VQ), initially introduced by Gray (1984), has recently seen a renaissance in the context of learning discrete representations with neural networks. Spurred by the success of VQ-VAE (Van Den Oord et al., 2017), Esser et al. (2020) and Villegas et al. (2022) showed that training an autoregressive transformer on the representations of a VQ-VAE trained with a GAN loss enables powerful image and video generation models, respectively.
At the same time, VQ has become popular component in image (Bao et al., 2021; Li et al., 2023) and audio (Baevski et al., 2019) representation learning, and is a promising building block for the next generation of multimodal large language models (Aghajanyan et al., 2022; Kim et al., 2023; Aghajanyan et al., 2023).
When training VQ-VAE, the goal is to learn a codebook \(\mathcal{C}\) whose elements induce a compressed, semantic representation of the input data (typically images). In the forward pass, an image \(x\) is encoded into a representation \(z\) (typically a sequence of feature vectors), and each vector in \(z\) quantized to (i.e., replaced with) the closest vector in \(\mathcal{C}\). The quantization operation is not differentiable. When training a VAE with VQ in the latent representation, Van Den Oord et al. (2017) use the straightthrough estimator (STE) (Bengio et al., 2013), copying the gradients from the decoder input to the encoder output, resulting in gradients to the encoder. Since this still does not produce gradients for the codebook vectors, they further introduce two auxiliary losses to pull the codeword vectors towards the (unquantized) representation vectors and vice-versa.
Components of VQ-VAE
The Vector Quantised-Variational AutoEncoder (VQ-VAE), differs from VAEs in two key ways: the encoder network outputs discrete, rather than continuous, codes; and the prior is learnt rather than static.
In VQ-VAE, we have:
An input image \(x \in \mathbb{R}^{H \times W \times 3}\) where \(H, W\) are the height and width of the image.
A latent embedding space \(\mathcal{E}=\left\{e_k\right\}_{k=1}^K \subset \mathbb{R}^{D}\), called the codebook, where each \(e_k\) is called a code and \(D\) is the dimensionality of codes.
An encoder \[ \begin{align} & \operatorname{E} : \mathbb{R}^{H \times W \times 3} \rightarrow \mathbb{R}^{h \times w \times D} \label{eq_encoder_1} \\ & \operatorname{E}(x) = z_e \label{eq_encoder_2} \end{align} \] encodes an image \(x\) into an embedding \(z_e\).
An operator called quantizer: \[ \begin{aligned} & \operatorname{Qtzr} : \mathbb{R}^{h \times w \times D} \rightarrow \mathbb{R}^{h \times w \times D} \\ & \operatorname{Qtzr}(z_e) = z_q , \end{aligned} \]
quantizes \(z_e\) to \(z_q\), where \(z_q, z_e \in \mathbb{R}^{h \times w \times D}\). The quantization process is \[ z_{q_{ij}} = {\arg\min} \|z_{e_{ij}} - e_k\| \] with subscript \(i, j\) starting from \(1\) to $ h, w$.
Therefore, for each element \(z_{e_{i j}}\) of \(z_e\), we use argmin to find the \(e_k\) that is closest in distance to \(z_{e_{i j}}\), i.e., minimizing the norm \(\left\|z_{e_{i j}}-e_k\right\|\), to get \(z_{q_{i,j}}\).
A decoder \[ \begin{align} & \operatorname{D} : \mathbb{R}^{h \times w \times D} \rightarrow \mathbb{R}^{H \times W \times 3} \label{eq_decoder_1} \\ & \operatorname{D}(z_q) = \hat x \label{eq_decoder_2} \end{align} \] decodes \(z_q\) into an image \(\hat x\), which is also called the reconstructed image of \(x\).
Forward pass
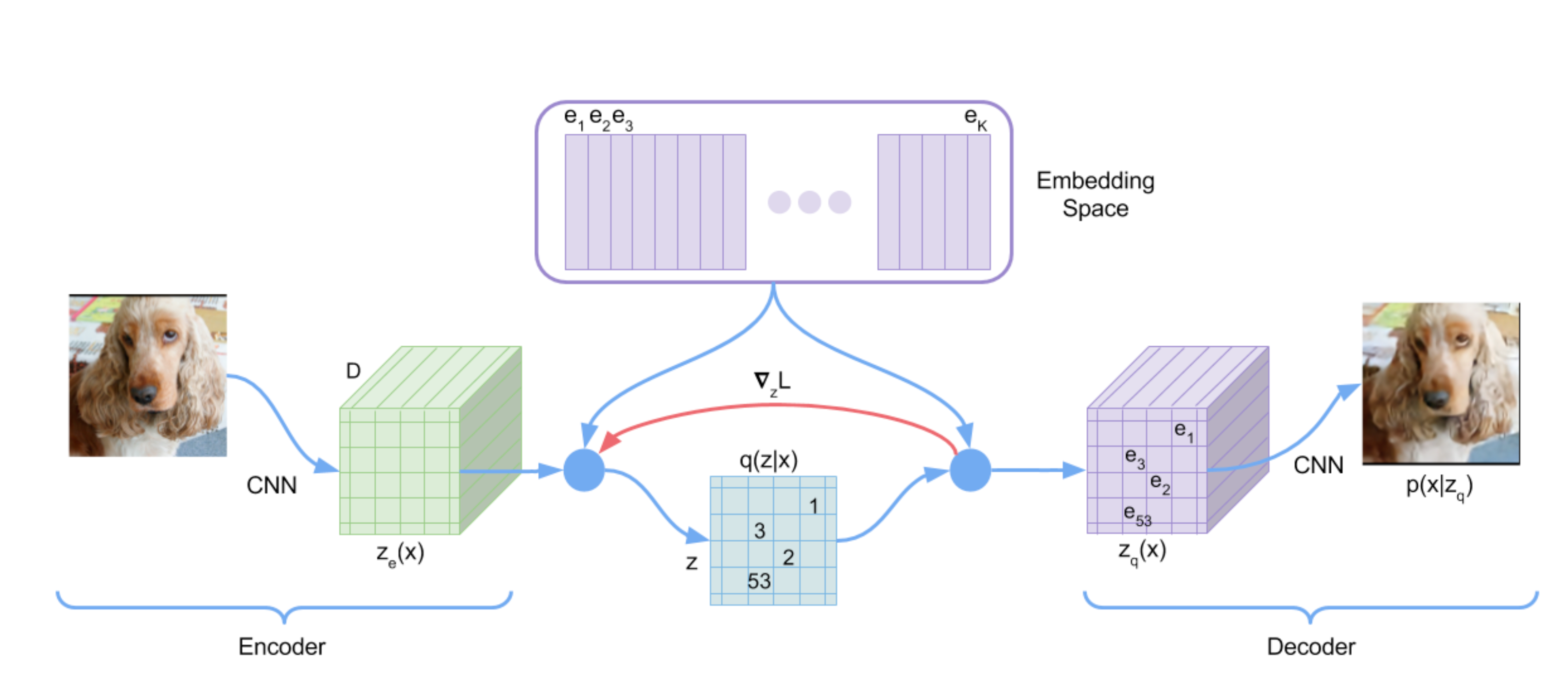
The forward pass of VQ-VAE consists of
First, we use encoder \(\operatorname{E(.)}\) to encode the input image \(x\) to get the embedding \(z_e\): \[ z_e = \operatorname{E}(x) . \]
Next, we use quantizer \(\operatorname{Qtzr}(.)\) to quantize the embedding \(z_e\) to get the quantized embedding \(z_q\). Since \(z_e\) contains \(h\times w\) embeddings, \(z_q\) is composed of \(h \times w\) codes, of which each code \(e_k\) is selected through a nearest-neighbor lookup (
argmin()) to the codebook \(\mathcal{E}=\left\{e_k\right\}_{k=1}^K\).Finnally, we use decoder to decode \(z_e\) to get the reconstructed image \(\hat x\).
NOTES:
The encoded embedding \(z_e\) and quantized embedding \(z_q\) have the same dimentionality \[ z_e, z_q \in \mathbb{R}^{h \times w \times D} . \] and they have the same embedding dimenstion (=\(D\)) as \(e_k\).
We will sometimes use \(z_e(x), z_q(x)\) to refer \(z_e, z_q\).
Loss function
The overall loss function is: \[
L=
\color{blue} {-\log p\left(x \mid z_q\right)} +
\color{green} {\left\|\operatorname{sg}(z_e -z_q) \right\|_2^2} +
\color{purple}{\beta\left\|z_e -\operatorname{sg}(z_q)\right\|_2^2},
\] Since VQ-VAE leverages argmin() function, which is non-differentiable. The gradient \(\nabla_{z_q} L\) from decoder input \({z}_q\) can not be passed to the encoder output \(\mathbf{z}_e\). To solve this, we use a trick called the straight through estimator which applies a stop_gradient operator (\(\operatorname{sg}\) in the equation) to copy \(\nabla_{z_q} L\) to \(z_e\).
The overall loss function has three components:
Reconstruction loss \(\color{blue} {-\log p\left(x \mid z_q\right)}\) is the negative log-likelihood. In practice, it's common to replace it with MSE loss.
Codebook loss \(\color{green} {\left\|\operatorname{sg}\left[z_e(x)\right]-e\right\|_2^2}\), which moves the embedding vectors towards the encoder output.
Commitment loss \(\color{purple}{\beta\left\|z_e(x)-\operatorname{sg}[e]\right\|_2^2}\), which encourages the encoder output to stay close to the embedding space.
Model architecture
#TODO shape problem
VectorQuantizer
This layer takes a tensor to be quantized. The channel dimension will be used as the space in which to quantize. All other dimensions will be flattened and will be seen as different examples to quantize.
The output tensor will have the same shape as the input.
As an example for a BCHW tensor of shape [16, 64, 32, 32], we will first convert it to an BHWC tensor of shape [16, 32, 32, 64] and then reshape it into [16384, 64] and all 16384 vectors of size 64 will be quantized independently. In otherwords, the channels are used as the space in which to quantize.
All other dimensions will be flattened and be seen as different examples to quantize, 16384 in this case.
1 | class VectorQuantizer(nn.Module): |
We will also implement a slightly modified version which will use exponential moving averages to update the embedding vectors instead of an auxillary loss. This has the advantage that the embedding updates are independent of the choice of optimizer for the encoder, decoder and other parts of the architecture. For most experiments the EMA version trains faster than the non-EMA version.
VectorQuantizerEMA
1 | class VectorQuantizerEMA(nn.Module): |
Encoder
1 | class Encoder(nn.Module): |
Decoder
1 | class Decoder(nn.Module): |
Residual blocks
1 | class Residual(nn.Module): |
VQ-VAE
1 | class Model(nn.Module): |