WaveNet: A Simple Illustration of Neural Networks
Sources:
- Building makemore Part 5: Building a WaveNet
- WaveNet 2016 from DeepMind
See my Github repo for the full implementation.
WaveNet
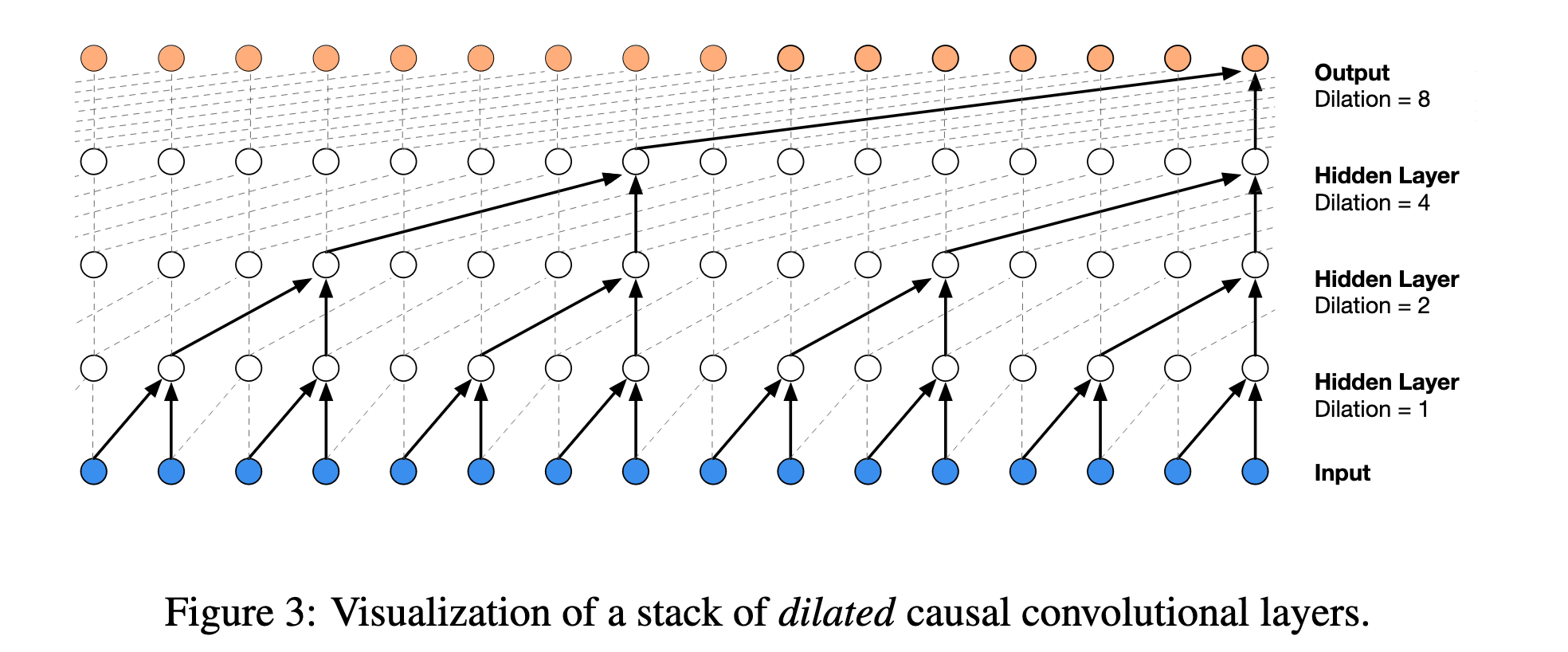
A wavenet is a neural network featuring a "dilated causal convolutional layers" architeture. Despite the fancy terminalogy, the nature is very simple: it converts each input sample, which is typically a time-sequence data and has a shape of T, to a output data with shape (V):
1 | [B, T] --> (WaveNet) --> [B, V] |
T: In WaveNet, each input sample of has shape[T]whereTis the time dimenstion (sequence length), i.e., each sample is a time sequence data, such as a sequence of words.B: In practice, the input samples are batched during training. So the shape of input data is[B, T]whereBis the batch dimenstion (batch size).V: The output of WaveNet is usually expected to be a logit of some probability, such as the probability for the next English character, in which caseV=26since the alphabet of English is 26.
Steps
The forward pass of WaveNet has following steps:
First, we use a embedding layer to create a embedding for each input sample. In the figure above, a embedding is created as a 16-D vector for a sample.
1
[B, T] --> [B, T, C]
where
Cis the embedding dimenstion.After that, use a flatten layer to flatten the embedding dimenstions by half. Thus, a 16-D embedding becomes a 8-D embedding.
1
[B, T, C] --> [B, T//2, C*2]
Do some other stuff, like applying batch norm and linear layers.
1
[B, T//2, C*2] --> [B, T//2, H]
where
His the hidden dimenstion in the MLP/linear layer.Repeat step 2-3 until the embedding dimenstion becomes 1. Then we sequeeze out this dimenstion and get the final result.
1
[B, T, C] --> [B, T//2, H] --> [B, T//4, H] --> ... --> [B, H]
At last, we apply a linear layer to align with the output shape.
1
[B, H] --> [B, V]
Code
Note: Some APIs and requirements are ommited. For details, please refer to my full implementation.
The code is quite compact, we just stack layers together. Note that in the previous figure we have 4 hidden layers converting the time dimenstion as 16 --> 8 --> 4 --> 2 --> 1, whereas in this code implementation, we only have 3 4 hidden layer, and the input time dimenstion is 8, instead of 16, i.e., 8 --> 4 --> 2 --> 1.
1 | # hierarchical network |
The WaveNet architecture is:
1 | model = Sequential([ |
The implementation of each class of layers can be seen in Appendix.
Training
Now we train the WaveNet. We apply following designes:
The maximun steps is set to 200000.
Loss fnction is set to cross entropy.
We use SGD as the optimizer and leverage learning rate decay, i.e.,
1
2
3lr = 0.1 if i < 150000 else 0.01 # step learning rate decay
for p in parameters:
p.data += -lr * p.grad
1 | # same optimization as last time |
We can visualize the loss during training:
1 | plt.plot(torch.tensor(lossi).view(-1, 1000).mean(1)) |
Inferrence
We can do inferrence, which means we can sample from the WaveNet (preciesely, from the probability distribution output by the WaveNet).
1 | # sample from the model |
Appendix
Linear
The linear layer used in this article is:
1 | class Linear: |
BatchNorm1d
The BatchNorm1d I used resembles PyTorch's torch.nn.BatchNorm1d (Source).
1 | class BatchNorm1d: |
Tanh
The Sequential class I used resembles PyTorch's torch.nn.Tanh (Source).
1 | class Tanh: |
Embedding
The Embedding class I used resembles PyTorch's torch.nn.Embedding (Source).
This module is often used to store word embeddings and retrieve them using indices. The input to the module is a list of indices, and the output is the corresponding word embeddings.
1 | class Embedding: |
Basic usage:
1 | ix = torch.randint(0, vocab_size, (3,)) # Get a batch of 3 samples. Each sample is a single integer index ranging from 0 to vocab_size-1, used to select one feature in the embedding matrix. |
FlattenConsecutive
The FlattenConsecutive class I used is similar to torch.nn.Flatten (Source).
It assumes that the input has shape [B, T, C], representing batch size, sequence length and channel number.
It accepts a flatten factor during initialization and will flatten the the sequence dimenstion (T) of each input according to that factor.
If the flattened sequence dimension becomes 1, it will be sequeezed out.
1 | class FlattenConsecutive: |
Sequential
The Sequential class I used resembles PyTorch's torch.nn.Sequential (Source). It is a sequential container for layers.
1 | class Sequential: |