Control Hazards in Pipelined Design
Sources:
- UWashington: CSE378, Lecture12
Note: the assembly code in this article can be MIPS or RISCV. This shouldn't be consufusing since the only big difference between them is that MIPS add a $ before the name of each register:
1 | # MIPS: |
Control hazards
- Most of the work for a branch computation is done in the EX stage.
- The branch target address is computed.
- The source registers are compared by the ALU, and the Zero flag is set or cleared accordingly.
- Thus, the branch decision cannot be made until the end of the EX stage.
- But we need to know which instruction to fetch next, in order to keep the pipeline running!
- This leads to what's called a control hazard.
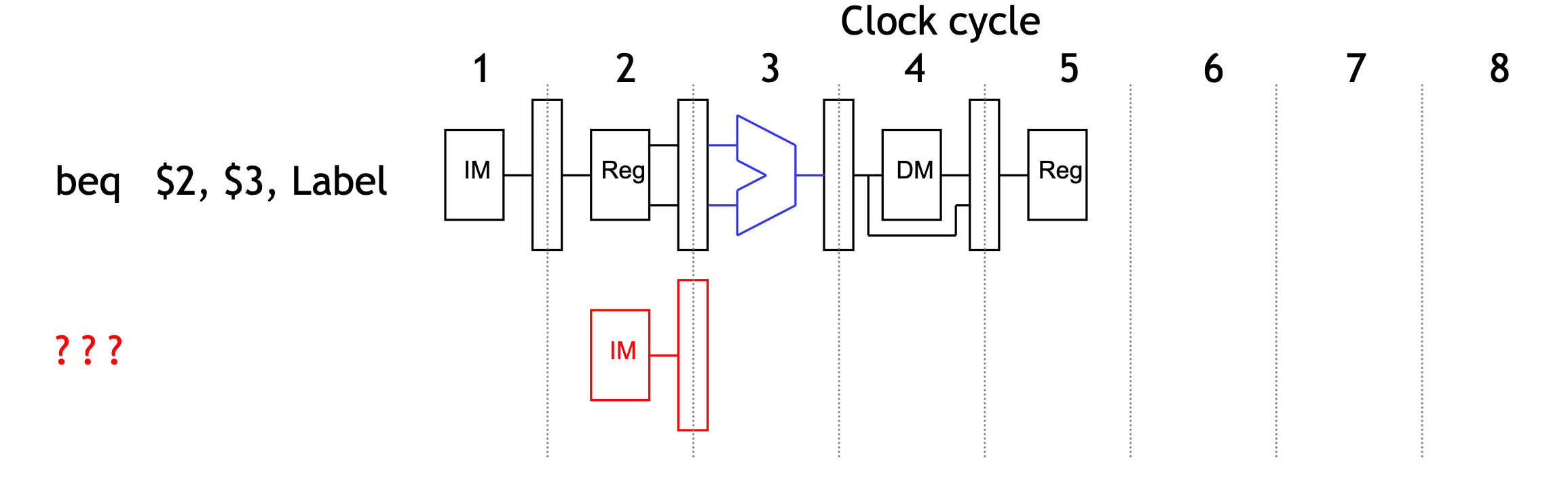
Stalling is one solution
Again, stalling is always one possible solution.
Here we just stall until cycle 4, after we do make the branch decision.
Branch prediction
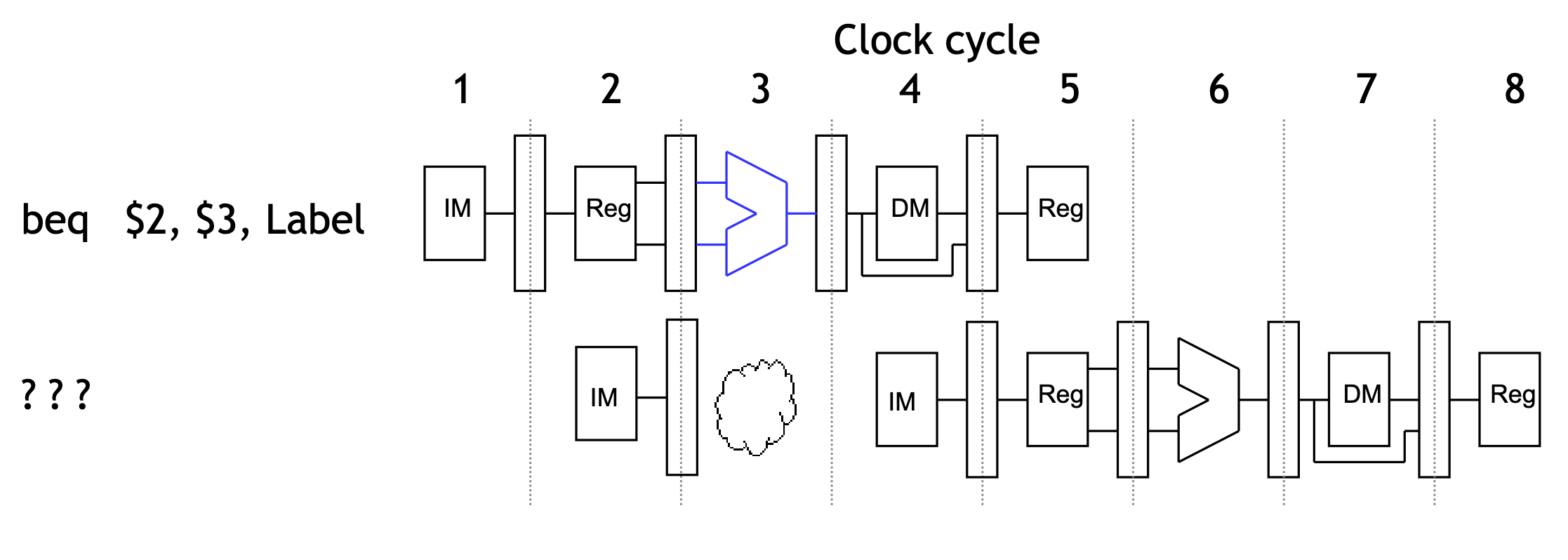
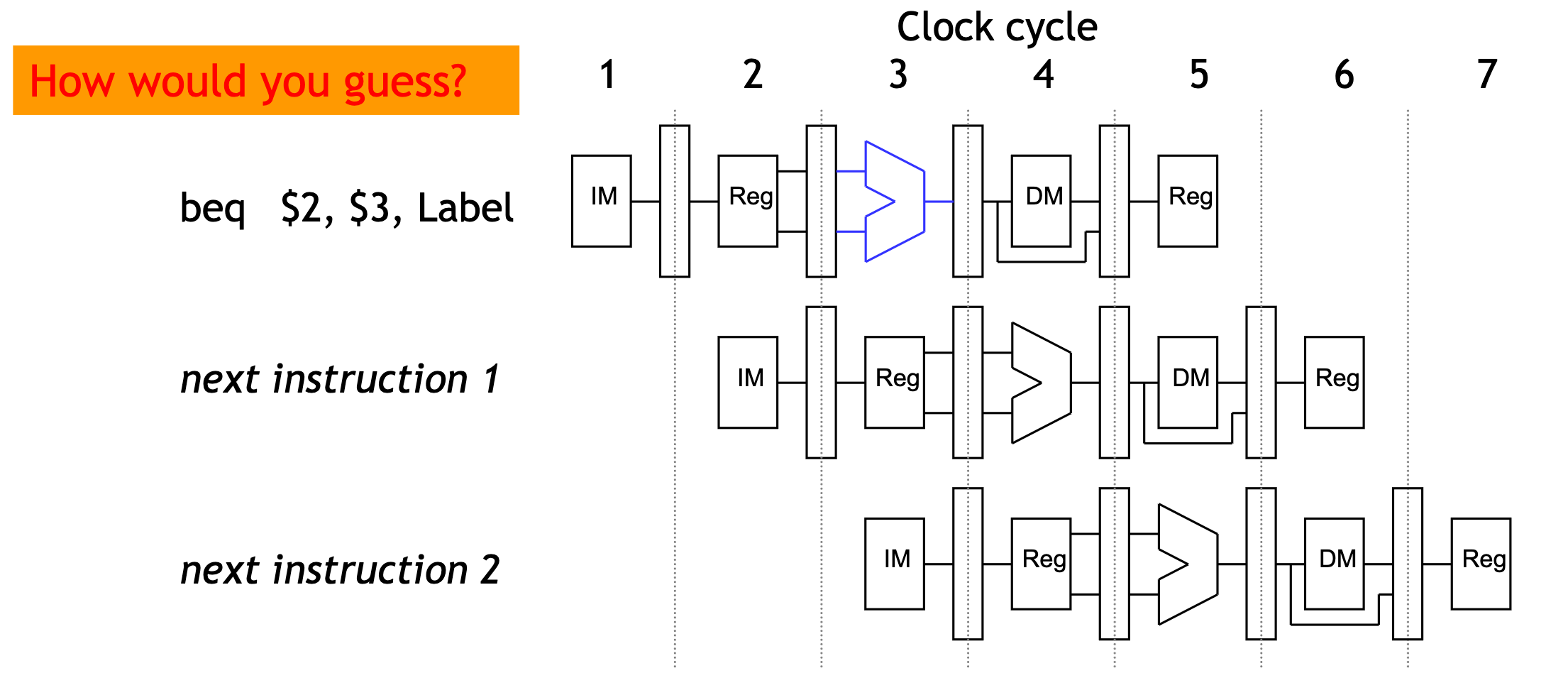
- Another approach is to guess whether or not the branch is taken.
- In terms of hardware, it’s easier to assume the branch is not taken.
- This way we just increment the PC and continue execution, as for normal instructions.
- If we’re correct, then there is no problem and the pipeline keeps going at full speed.
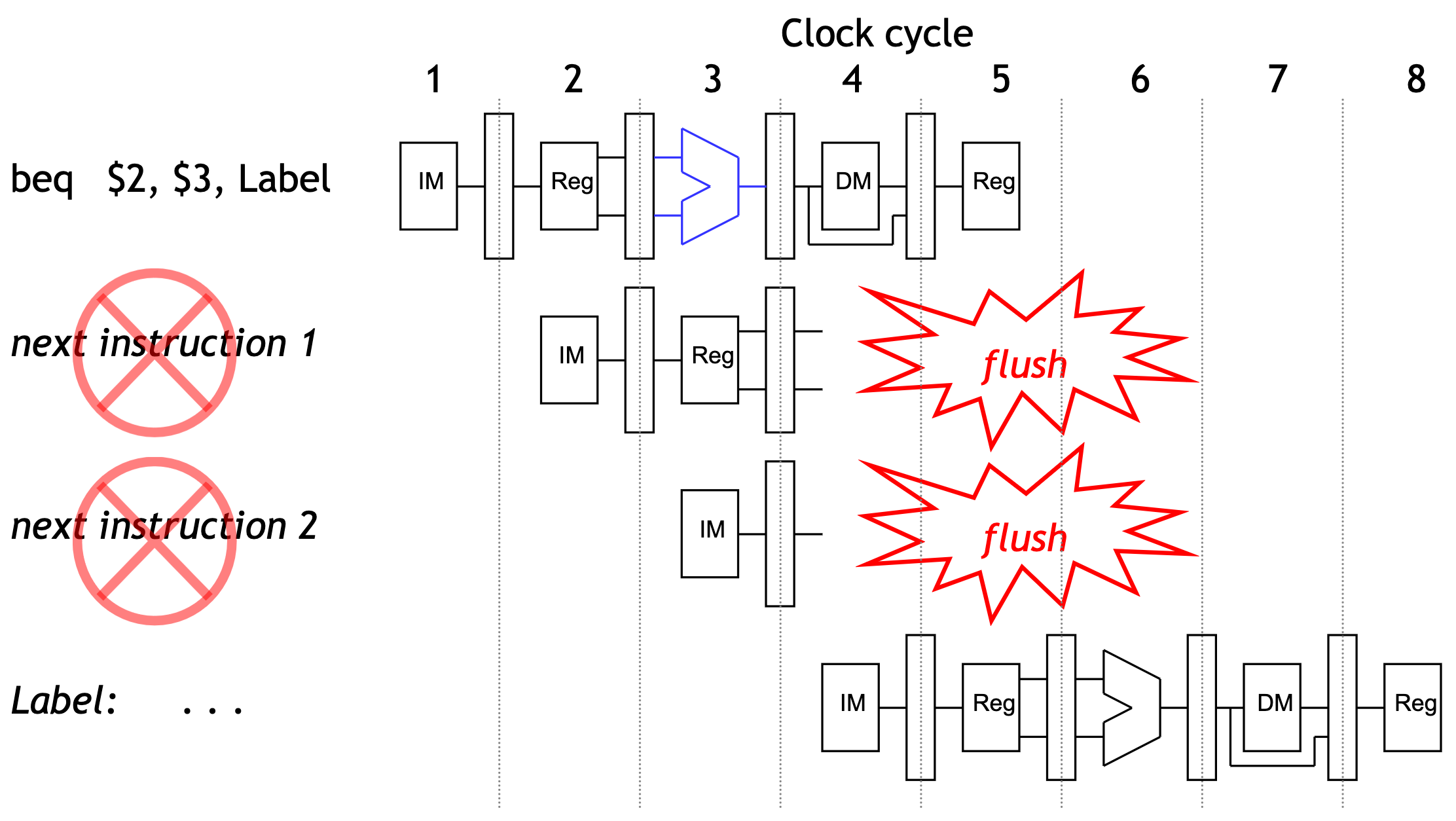
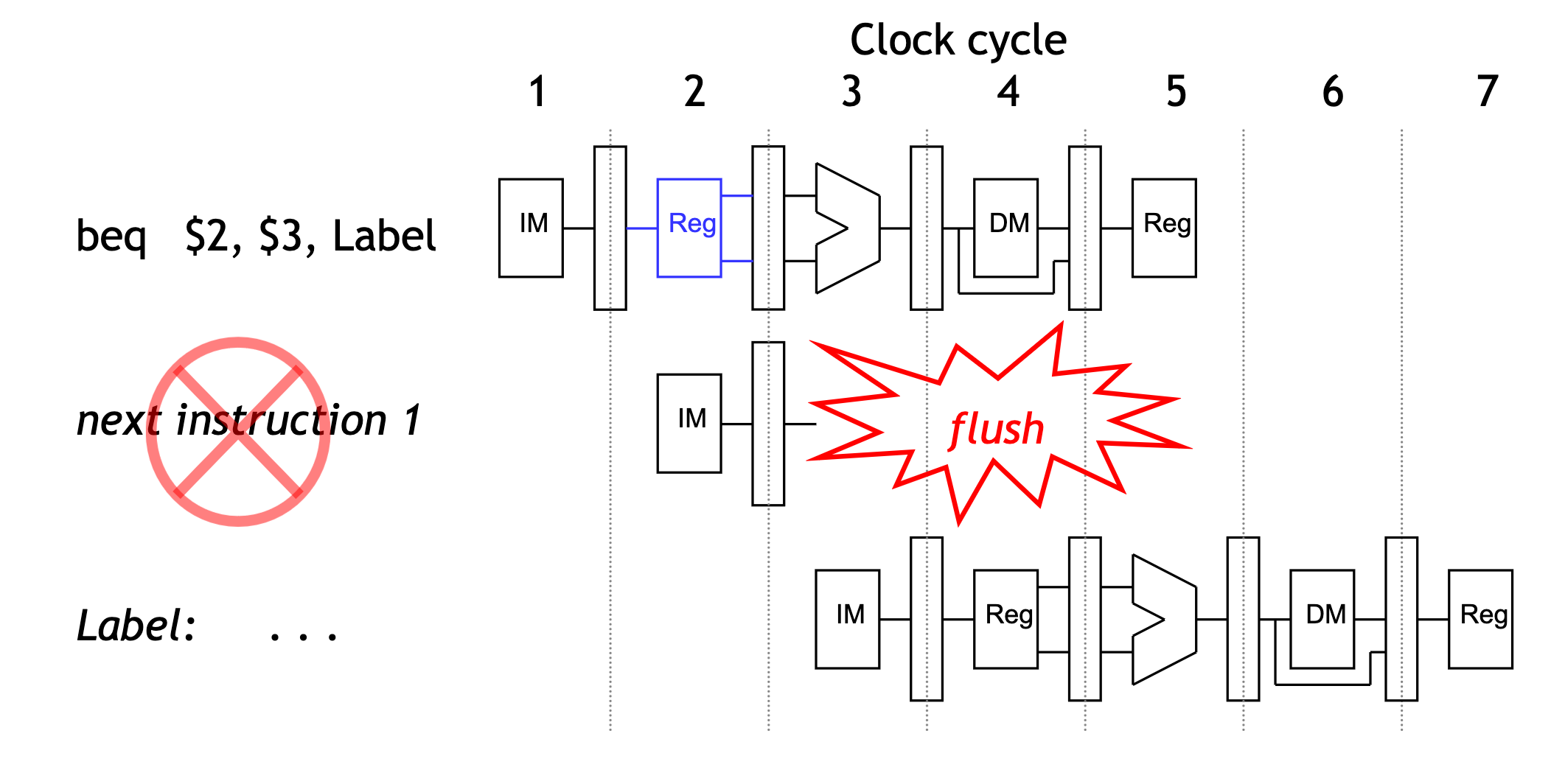
Branch misprediction
If our guess is wrong, then we would have already started executing two instructions incorrectly. We’ll have to discard, or flush, those instructions and begin executing the right ones from the branch target address, Label.
Performance gains and losse
- Overall, branch prediction is worth it.
- Mispredicting a branch means that two clock cycles are wasted.
- But if our predictions are even just occasionally correct, then this is preferable to stalling and wasting two cycles for every branch.
- All modern CPUs use branch prediction.
- The pipeline structure also has a big impact on branch prediction.
- A longer pipeline may require more instructions to be flushed for a misprediction, resulting in more wasted time and lower performance.
- We must also be careful that instructions do not modify registers or memory before they get flushed.
Implementing branches
- We can actually decide the branch a little earlier, in ID instead of EX.
- Our sample instruction set has only a BEQ.
- We can add a small comparison circuit to the ID stage, after the source registers are read.
- Then we would only need to flush one instruction on a misprediction.
If no prediction:
1 | IF ID EX MEM WB |
If prediction:
1 | If Correct |
Implementing flushes
- We must flush one instruction (in its IF stage) if the previous instruction is BEQ and its two source registers are equal.
- We can flush an instruction from the IF stage by replacing it in the IF/ID pipeline register with a harmless nop instruction.
- Flushing introduces a bubble into the pipeline, which represents the one- cycle delay in taking the branch