Multivariate Gaussian Distributions
Sources:
- The Multivariate Gaussian Distribution
Notation
The notations of this article is exactly the same as these in Univariate Gaussian Distributions. For the multi variate case, we add additional rules:
The multivariate normal distribution of a \(n\)-dimensional random vector \(\vec{X} = \left[X_1, \ldots, X_k\right]^{\mathrm{T}}\) can be written in the following notation: \[ \vec{X} \sim \mathcal{N}(\vec{\mu}, {\Sigma}) \] or to make it explicitly known that \(\vec{X}\) is \(k\)-dimensional, \[ \vec{X} \sim \mathcal{N}_k(\vec{\mu}, {\Sigma}) \] where \(\vec{\mu}\) and \(\Sigma\) are the expectation and variance of \(\vec{X}\). Since \(\vec{X}\) is a random vector, \(\Sigma\) is a variance-covariance matrix (or simply covariance matrix).
The PDF1 \(f_\vec{X}(\vec{x})\) is often denoted as \(p_\vec{X}(\vec{x})\), \(f_\vec{X}\left(\vec{x} ; \vec{\mu}, \sigma^2\right)\) or \(p_\vec{X}\left(\vec{x} ; \vec{\mu}, \sigma^2\right)\) where \(\vec{X} = \left[X_1, \ldots, X_k\right]^{\mathrm{T}}\). We sometimes omit the subscript \(\vec{X}\).
We use underline to show the importance of some symbols. For instance, \(\underline{X}\) to show the importance of \(X\).
Multivariate Gaussian distributions
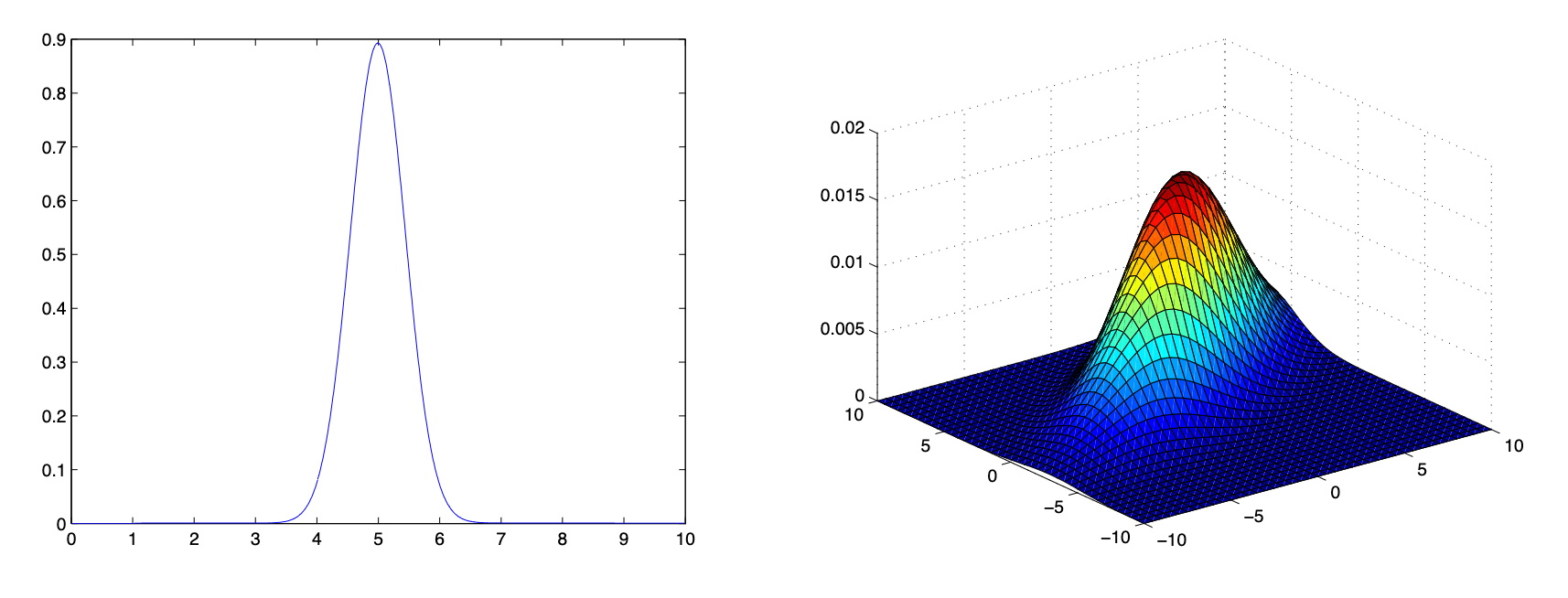
Figure 1: The figure on the left shows a univariate Gaussian density for a single variable X. The figure on the right shows a multivariate Gaussian density over two variables X1 and X2.
The multivariate normal distribution of a \(k\)-dimensional random vector \(\vec{X} = \left[X_1, \ldots, X_k\right]^{\mathrm{T}}\) can be written in the following notation: \[ \vec{X} \sim \mathcal{N}(\vec{\mu}, {\Sigma}) \] or to make it explicitly known that \(X\) is \(k\)-dimensional, \[ \vec{X} \sim \mathcal{N}_k(\vec{\mu}, {\Sigma}) \] The inverse of the covariance matrix is called the precision matrix, denoted by \({Q}={\Sigma}^{-1}\).
The PDF is: \[ f_{\vec{X}}(\vec{x}; {\mu}, {\Sigma}) = \frac{1}{(2 \pi)^{n / 2}|\Sigma|^{1 / 2}} \exp \left(-\frac{1}{2}(\vec{x}-\vec{\mu})^T \Sigma^{-1}(\vec{x}-\vec{\mu})\right) \]
where \(\exp\) denotes the exponential function.
Note:
- \(\det({\Sigma})\) is the determinant of the covariance matrix.
- \({\Sigma}^{-1}\) is the inverse of the covariance matrix.
Isocontours
One way to understand a multivariate Gaussian conceptually is to understand the shape of its isocontours. For a function \(f: \mathbf{R}^2 \rightarrow \mathbf{R}\), an isocontour is a set of the form \[ \left\{\vec{x} \in \mathbf{R}^2: f(x)=c\right\} . \] for some \(c \in \mathbf{R}{ }^4\).
Shape of isocontours
What do the isocontours of a multivariate Gaussian look like? As before, let's consider the case where \(n=2\), and \(\Sigma\) is diagonal, i.e., all the random variables \(X_i\) in \(\vec{X}\) are independent (see my post).
Let's take the example of \[ \vec{x}=\left[\begin{array}{l} x_1 \\ x_2 \end{array}\right] \quad \vec{\mu}=\left[\begin{array}{l} \mu_1 \\ \mu_2 \end{array}\right] \quad \Sigma=\left[\begin{array}{cc} \sigma_1^2 & 0 \\ 0 & \sigma_2^2 \end{array}\right] \]
The PDF is \[ f(\vec{x} ; \mu, \Sigma)=\frac{1}{2 \pi \sigma_1 \sigma_2} \exp \left(-\frac{1}{2 \sigma_1^2}\left(x_1-\mu_1\right)^2-\frac{1}{2 \sigma_2^2}\left(x_2-\mu_2\right)^2\right) . \]
Now, let's consider the level set consisting of all points where \(p(x ; \mu, \Sigma)=c\) for some constant \(c \in \mathbf{R}\). In particular, consider the set of all \(x_1, x_2 \in \mathbf{R}\) such that \[ \begin{aligned} c & =\frac{1}{2 \pi \sigma_1 \sigma_2} \exp \left(-\frac{1}{2 \sigma_1^2}\left(x_1-\mu_1\right)^2-\frac{1}{2 \sigma_2^2}\left(x_2-\mu_2\right)^2\right) \\ 2 \pi c \sigma_1 \sigma_2 & =\exp \left(-\frac{1}{2 \sigma_1^2}\left(x_1-\mu_1\right)^2-\frac{1}{2 \sigma_2^2}\left(x_2-\mu_2\right)^2\right) \\ \log \left(2 \pi c \sigma_1 \sigma_2\right) & =-\frac{1}{2 \sigma_1^2}\left(x_1-\mu_1\right)^2-\frac{1}{2 \sigma_2^2}\left(x_2-\mu_2\right)^2 \\ \log \left(\frac{1}{2 \pi c \sigma_1 \sigma_2}\right) & =\frac{1}{2 \sigma_1^2}\left(x_1-\mu_1\right)^2+\frac{1}{2 \sigma_2^2}\left(x_2-\mu_2\right)^2 \\ 1 & =\frac{\left(x_1-\mu_1\right)^2}{2 \sigma_1^2 \log \left(\frac{1}{2 \pi c \sigma_1 \sigma_2}\right)}+\frac{\left(x_2-\mu_2\right)^2}{2 \sigma_2^2 \log \left(\frac{1}{2 \pi c \sigma_1 \sigma_2}\right)} . \end{aligned} \]
Defining \[ r_1=\sqrt{2 \sigma_1^2 \log \left(\frac{1}{2 \pi c \sigma_1 \sigma_2}\right)} \quad r_2=\sqrt{2 \sigma_2^2 \log \left(\frac{1}{2 \pi c \sigma_1 \sigma_2}\right)}, \] it follows that \[ \begin{equation} \label{ellipse} \color{teal}{1=\left(\frac{x_1-\mu_1}{r_1}\right)^2+\left(\frac{x_2-\mu_2}{r_2}\right)^2} . \end{equation} \]
Equation \(\eqref{ellipse}\) is the equation of an axis-aligned ellipse, with center \(\left(\mu_1, \mu_2\right)\), where the \(x_1\) axis has length \(2 r_1\) and the \(x_2\) axis has length \(2 r_2\). ## Length of axes
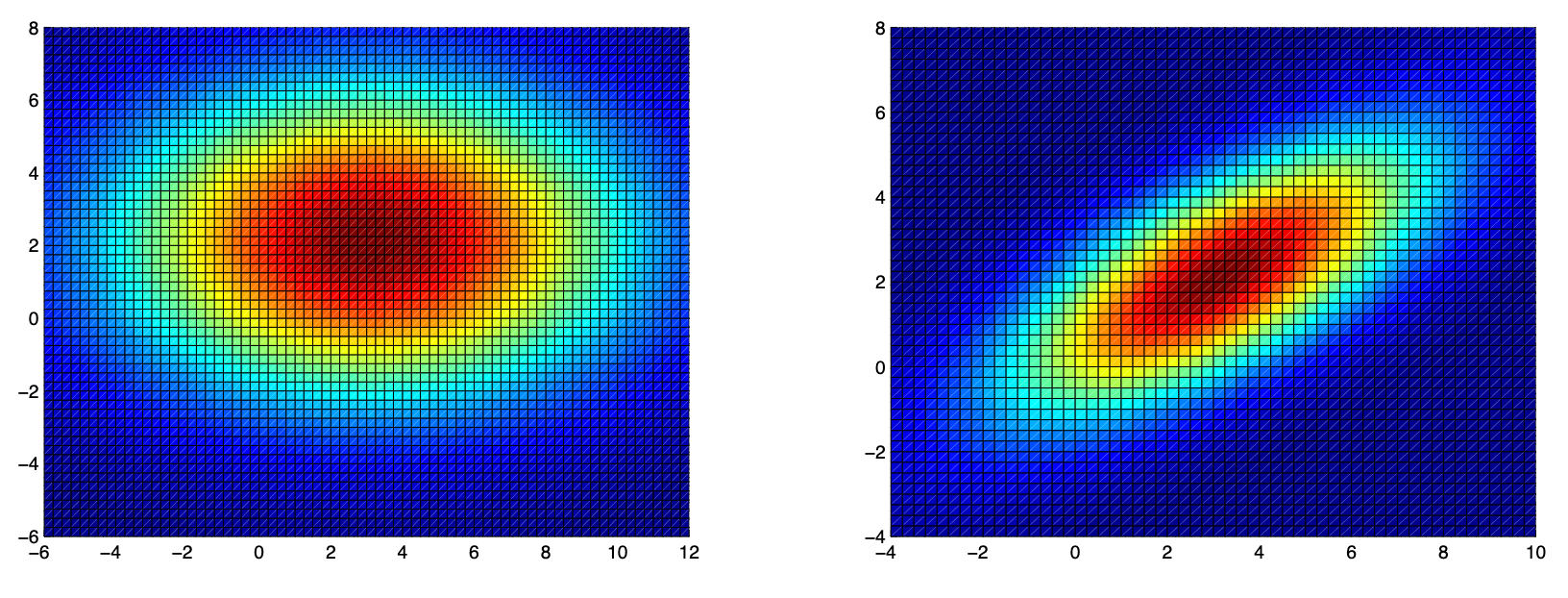
To get a better understanding of how the shape of the level curves vary as a function of the variances of the multivariate Gaussian distribution, suppose that we are interested in
The figure on the left shows a heatmap indicating values of the density function for an axis-aligned multivariate Gaussian with mean \(\mu=\left[\begin{array}{l}3 \\ 2\end{array}\right]\) and diagonal covariance matrix \(\Sigma=\) \(\left[\begin{array}{cr}25 & 0 \\ 0 & 9\end{array}\right]\). Notice that the Gaussian is centered at \((3,2)\), and that the isocontours are all elliptically shaped with major/minor axis lengths in a 5:3 ratio.
The figure on the right shows a heatmap indicating values of the density function for a non axis-aligned multivariate Gaussian with mean \(\mu=\left[\begin{array}{l}3 \\ 2\end{array}\right]\) and covariance matrix \(\Sigma=\left[\begin{array}{cc}10 & 5 \\ 5 & 5\end{array}\right]\). Here, the ellipses are again centered at \((3,2)\), but now the major and minor axes have been rotated via a linear transformation (because its covariance matrix isn't diagonal), the values of \(r_1\) and \(r_2\) at which \(c\) is equal to a fraction \(1 / e\) of the peak height of Gaussian density.
First, observe that maximum of Equation (4) occurs where \(x_1=\mu_1\) and \(x_2=\mu_2\). Substituting these values into Equation (4), we see that the peak height of the Gaussian density is \(\frac{1}{2 \pi \sigma_1 \sigma_2}\). Second, we substitute \(c=\frac{1}{e}\left(\frac{1}{2 \pi \sigma_1 \sigma_2}\right)\) into the equations for \(r_1\) and \(r_2\) to obtain \[ \begin{aligned} & r_1=\sqrt{2 \sigma_1^2 \log \left(\frac{1}{2 \pi \sigma_1 \sigma_2 \cdot \frac{1}{e}\left(\frac{1}{2 \pi \sigma_1 \sigma_2}\right)}\right)}=\sigma_1 \sqrt{2} \\ & r_2=\sqrt{2 \sigma_2^2 \log \left(\frac{1}{2 \pi \sigma_1 \sigma_2 \cdot \frac{1}{e}\left(\frac{1}{2 \pi \sigma_1 \sigma_2}\right)}\right)}=\sigma_2 \sqrt{2} . \end{aligned} \]
From this, it follows that the axis length needed to reach a fraction 1/e of the peak height of the Gaussian density in the \(i\) th dimension grows in proportion to the standard deviation \(\sigma_i\). Intuitively, this again makes sense: the smaller the variance of some random variable \(x_i\), the more "tightly" peaked the Gaussian distribution in that dimension, and hence the smaller the radius \(r_i\).
Linear Linear transformation interpretation
Theorem: Let \(X \sim \mathcal{N}(\mu, \Sigma)\) for some \(\mu \in \mathbf{R}^n\) and \(\Sigma \in \mathbf{S}_{++}^n\). Then, there exists a matrix \(B \in \mathbf{R}^{n \times n}\) such that if we define \(Z=B^{-1}(X-\mu)\), then \(Z \sim \mathcal{N}(0, I)\).
Proof:
- As before said, if \(Z \sim \mathcal{N}(0, I)\), then it can be thought of as a collection of \(n\) independent standard normal random variables (i.e., \(Z_i \sim \mathcal{N}(0,1)\) ).
- Furthermore, if \(Z=B^{-1}(X-\mu)\) then \(X=B Z+\mu\) follows from simple algebra.
- Consequently, the theorem states that any random variable \(X\) with a multivariate Gaussian distribution can be interpreted as the result of applying a linear transformation \((X=\) \(B Z+\mu)\) to some collection of \(n\) independent standard normal random variables \((Z)\).
Probability density function↩︎