Data Compression
Ref:
- EE 376A: Information Theory. Winter 2018. Lecture 6. - Stanford University
- EE 376A: Information Theory. Winter 2017. Lecture 4. - Stanford University
- Elements of Information Theory
Notations
- rv: random variable.
- Let \(x^n\) denote \(\left(x_1, x_2, \ldots, x_n\right)\).
Codes
Definition: A source code \(C\) for a random variable \(X\) is a mapping from \(\mathcal{X}\), the range of \(X\), to \(\mathcal{D}^*\), the set of finite-length strings of symbols from a \(D\)-ary alphabet. Let \(C(x)\) denote the codeword corresponding to \(x\) and let \(l(x)\) denote the length of \(C(x)\).
- That is, a code \(C\) of rv \(X\) is a function from \(\mathcal X\) to \(\mathcal D^*\).
- For example, \(C(\) red \()=00, C(\) blue \()=11\) is a source code for \(\mathcal{X}=\{\) red, blue \(\}\) with alphabet \(\mathcal{D}=\{0,1\}\).
Definition: The expected length \(L(C)\) of a source code \(C(x)\) for a random variable \(X\) with probability mass function \(p(x)\) is given by \[ L(C)= \mathbb E(l(x))= \sum_{x \in \mathcal{X}} p(x) l(x) \] where \(l(x)\) is the length of the codeword associated with \(x\).
Definition: The extension \(C^*\) of a code \(C\) is a function of stochastic process \(X^n\). \[ C^*(x^n) =C\left(x_1\right) C\left(x_2\right) \cdots C\left(x_n\right), \] where \(C\left(x_1\right) C\left(x_2\right) \cdots C\left(x_n\right)\) indicates concatenation of the corresponding codewords.
- Example: If \(C\left(x_1\right)=00\) and \(C\left(x_2\right)=11\), then \(C\left(x_1 x_2\right)=0011\).
- Note: For convience, we'll use the notation \(C(x^n)\) instead of \(C^*(x^n)\).
Example
Without loss of generality, we can assume that the \(D\)-ary alphabet is \(\mathcal{D}=\{0,1, \ldots, D-1\}\).
Let \(X\) be a rv with the following distribution and codeword assignment: \[ \begin{array}{ll} \operatorname{Pr}(X=1)=\frac{1}{2}, & \text { codeword } C(1)=0 \\ \operatorname{Pr}(X=2)=\frac{1}{4}, & \text { codeword } C(2)=10 \\ \operatorname{Pr}(X=3)=\frac{1}{8}, & \text { codeword } C(3)=110 \\ \operatorname{Pr}(X=4)=\frac{1}{8}, & \text { codeword } C(4)=111 . \end{array} \]
The entropy \(H(X)\) of \(X\) is 1.75 bits: \[ \begin{aligned} H(X) & = \mathbb E(l(x)) \\ & = p(X=1) \log \frac{1}{p(X=1)} + p(X=2) \log \frac{1}{p(X=2)} + p(X=3) \log \frac{1}{p(X=3)} + p(X=4) \log \frac{1}{p(X=4)} \\ & = (1/2 \cdot 1) + (1/4 \cdot 2) + (1/8 \cdot 3) + (1/8 \cdot 3) \\ & = 1.75 \end{aligned} \]
The expected length \(L(C)= \mathbb E(l(x))\) of this code is also 1.75 bits: \[ \begin{aligned} L(C) & = \mathbb E(l(x)) \\ & = p(X=1)l(X=1) + p(X=2)l(X=2) + p(X=3)l(X=3) + p(X=4)l(X=4) \\ & = (1 \cdot 1/2) + (2 \cdot 1/4) + (3 \cdot 1/8) + (3 \cdot 1/8) \\ & = 1.75 \end{aligned} \]
Here we have a code that has the same average length as the entropy. We note that any sequence of bits can be uniquely decoded into a sequence of symbols of \(X\). For example, the bit string 0110111100110 is decoded as 134213.
Classes of Codes
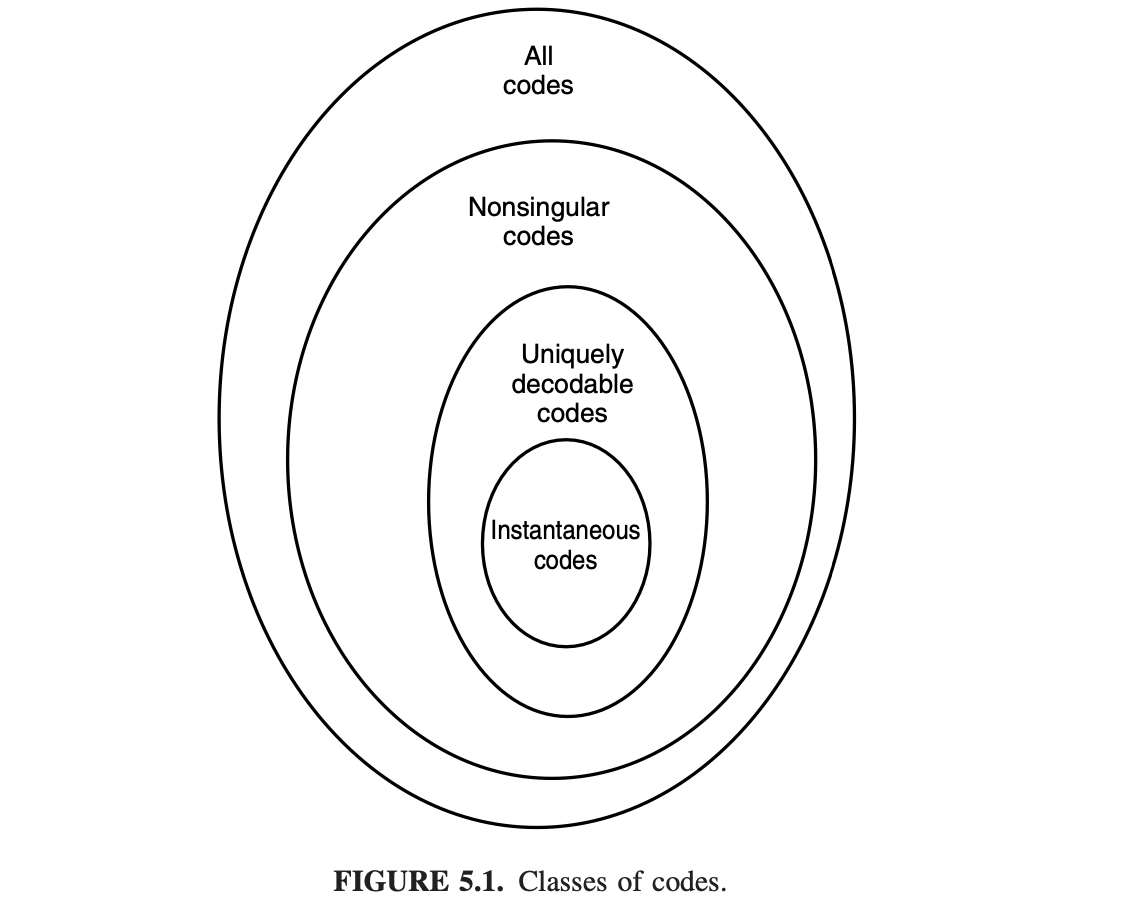
Nonsingular Codes
Definition: A code is said to be nonsingular if it's an injection; i.e., every element of the range of \(X\) maps into a different string in \(\mathcal{D}^*\). \[ x \neq x^{\prime} \Rightarrow C(x) \neq C\left(x^{\prime}\right) . \]
Nonsingularity suffices for an unambiguous description of a single value of \(X\).
But we usually wish to send a sequence of values of \(X\). In such cases we can ensure decodability by adding a special symbol (a "comma") between any two codewords.
But this is an inefficient use of the special symbol; we can do better by developing the idea of self-punctuating or instantaneous codes.
Uniquely Decodable
Definition: A code is called uniquely decodable if its extension is an injection(nonsingular); i.e, every element of the range of \(X^n\) maps into a different string.
However, one may have to look at the entire string to determine even the first symbol in the corresponding source string.
Prefix Codes
Definition: A code is called a prefix code or an instantaneous code if no codeword is a prefix of any other codeword.
- A prefix code is uniquely decodable and self-punctuating(i.e. without needing entire binary sequence before decoding starts)
Example
To illustrate the differences between the various kinds of codes, consider the examples of codeword assignments \(C(x)\) to \(x ∈ \mathcal X\) in following table:
| \(X\) | Singular | Nonsingular, But Not Uniquely Decodable | Uniquely Decodable But Not Instantaneous | Instantaneous |
|---|---|---|---|---|
| 1 | 0 | 0 | 10 | 0 |
| 2 | 0 | 010 | 00 | 10 |
| 3 | 0 | 01 | 11 | 110 |
| 4 | 0 | 10 | 110 | 111 |
For the nonsingular code, the code string 010 has three possible source sequences:
- 2
- 14
- 31
and hence the code is not uniquely decodable.
For the uniquely decodable code but not prefix-free code:
- If the first two bits are 00 or 10, they can be decoded immediately.
- If the first two bits are 11, we must look at the following bits.
- If the next bit is a 1, the first source symbol is a 3.
- If the length of the string of 0’s immediately following the 11 is odd, the first codeword must be 110 and the first source symbol must be 4;
- if the length of the string of 0’s is even, the first source symbol is a 3.
By repeating this argument, we can see that this code is uniquely decodable. Sardinas and Patterson [455] have devised a finite test for unique decodability, which involves forming sets of possible suffixes to the codewords and eliminating them systematically.
The fact that the last code in Table 5.1 is instantaneous is obvious since no codeword is a prefix of any other.
Kraft-McMillan Inequality
Theorem: (Kraft-McMillan Inequality). For all D-ary uniquely decodable (UD) codes:
\[ \begin{equation} \label{eq_Kraft-McMillan_Inequality} \sum_{x \in \mathcal{X}} D^{-l(x)} \leq 1 \end{equation} \]
Converse: any integer-valued function satisfying this inequality is the length function of some UD code.
Note since every prefix code is uniquely decodable, this inequality also holds for prefix codes.
Sometimes this equation is written as \(\sum D^{-l_{i}} \leq 1\).
Proof
Take any uniquely decodable code and let \(l_{\max }=\max l(x)\). Fix any integer \(k\) and observe: \[ \begin{aligned} \left(\sum_{x \in \mathcal{X}} D^{-l(x)}\right)^k & =\left(\sum_{x_1} D^{-l\left(x_1\right)}\right) \cdot\left(\sum_{x_2} D^{-l\left(x_2\right)}\right) \cdot \ldots \cdot\left(\sum_{x_k} D^{-l\left(x_k\right)}\right) \\ & =\sum_{x_1} \sum_{x_2} \ldots \sum_{x_k} \prod_{i=1}^k D^{-l\left(x_i\right)} \\ & =\sum_{x_1, \ldots x_k} D^{-\sum_{i=1}^k l\left(x_i\right)} \\ & =\sum_{x^k \in \mathcal X^k} D^{-l\left(x^k\right)} \\ & =\sum_{m=1}^{k \cdot l_{\max }} a(m) \cdot D^{-m} \end{aligned} \]
Explain:
- The transition from 1st to 2nd line is that we just assign index 1,2,...,k to \(x\). //TODO
- \(l(x^k)\) is the length of the string/sequence \(x^k\)(or \(x_1,x_2,\cdots,x_k\)).
- \(a(m)\) is the number of source sequences xk mapping into codewords of length \(m\).
Since the code is uniquely decodable, the mapping is one-to-one, so:
- there is at most one sorce symbol sequence mapping into each code \(m\)-length codeword sequence
- and there are at most \(D^m\) code \(m\)-length codeword sequence.
Thus, \(a(m) ≤ D^m\), and we have \[ \sum_{m=1}^{k \cdot l_{\max }} a(m) \cdot D^{-m} \le \sum_{m=1}^{k \cdot l_{\max }} D^m \cdot D^{-m} = kl_{\max } . \]
So we can get an upper-bound: \[ \left(\sum_{x \in \mathcal{X}} 2^{-l(x)}\right)^k \leq \sum_{m=1}^{k \cdot l_{\max }} D^m \cdot D^{-m}=k \cdot l_{\max } \]
Notice that the exponential term \(\left(\sum_{u \in \mathcal{U}} 2^{-l(u)}\right)^k\) is in fact upper-bounded by \(k \cdot l_{\text {max }}\), which is linear in \(k\).
From this we arrive at the theorem's claim (note that the inequality holds for all \(k>0\) ): \[ \sum_{x \in \mathcal{X}} 2^{-l(x)} \leq \lim _{k \rightarrow \infty}\left(k \cdot l_{\max }\right)^{1 / k}=1 \]
Proof of Converse
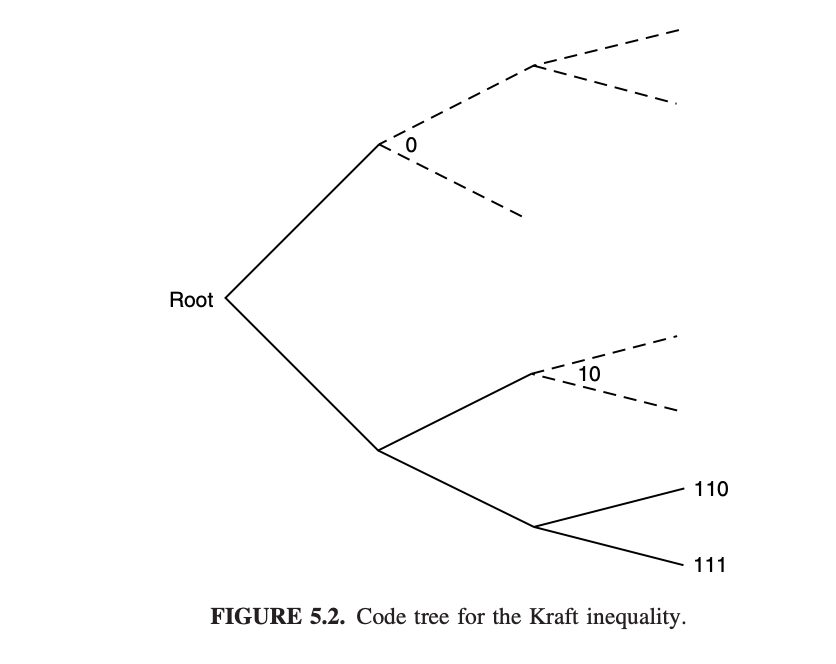
Proof of converse: given any set of \(l_1, l_2, . . . , l_m\) satisfying the Kraft-McMillan Inequality, we can construct an prefix code as:
Consider a D-ary tree in which each node has D children. Let the branches of the tree represent the symbols of the codeword. Then each codeword is represented by a leaf on the tree. The path from the root traces out the symbols of the codeword.
Note: no codeword is an ancestor of any other codeword on the tree. So that it's a prefix tree.
Note: even for a "leaf", we continue to write its descendants.
Label the first node (lexicographically) of depth \(l_1\) as codeword 1, and remove its descendants from the tree. Note: for \(i \ne j\), \(l_i\) may equal to \(l_j\).
Then label the first remaining node of depth \(l_2\) as codeword 2, and so on.
Proceeding this way, we construct a prefix code with the specified \(l_1, l_2, . . . , l_m\).
Optimal Codes
An optimal code is a prefix code with the minimum expected length.
From the results of Kraft-McMillan Inequality, this is equivalent to finding the set of lengths \(l_{1}, l_{2}, \ldots, l_{m}\) with minimum expected length while satisfying the Kraft-McMillan Inequality.
This is a standard optimization problem: Minimize \[ L=\sum p_{i} l_{i} \] over all integers \(l_{1}, l_{2}, \ldots, l_{m}\) satisfying \[ \sum D^{-l_{i}} \leq 1 \]
Bounds on the Optimal Code Length
Theorem: The expected length \(L\) of any uniquely decodable (UD) D-ary code for a random variable \(X\) is \[ \begin{equation} \label{eq_bound} H_D(X) \le L \le H_D(X) + 1 \end{equation} \]
Proof: \(H_D(X) \le L\)
Let \(q(x)=c 2^{-l(x)}\) be a P.M.F. where the normalizing constant \(c\) is chosen such that the probability sums to 1 .
We knwo that \(c \geq 1\).
Proof:
- By the Kraft-McMillan Inequality \(\eqref{eq_Kraft-McMillan_Inequality}\), \(\sum_{x \in \mathcal{X}} D^{-l(x)} \leq 1\).
- Since \(q(x)=c \cdot 2^{-l(x)}\), \(c=\frac{1}{\sum_{x \in \mathcal{X}} D^{-l(x)}}\), so \(c\ge1.\)
Next, consider the relative entropy between the probability distributions of the source \(p\) and \(q\) (Taking advantage of ): \[ \begin{aligned} 0 & \leq D(p \| q) \\ & =\sum_x p(x) \log_D \frac{p(x)}{q(u)} \\ & =\sum_x p(x) \log_D p(x)+\sum_x p(x) \log_D \frac{1}{q(u)} \\ & =\sum_x p(x) \log_D p(x)+\sum_x p(x)[l(u)-\underbrace{\log_D c}_{\geq 0}] \\ & \leq-H(X) + L \end{aligned} \]
Explain:
- The first line is from the non-negativity of relative entropy.
- The last line is due to \(H(X) = -\sum_x p(x) \log p(x)\) and \(L=\sum_x p(x)l(u)\).
- \(\log_D c \ge 0\) is from the fact that \(c \ge 1\).
Note: Beyond its role in this proof, the relative entropy has significance in the context of compression. Suppose we have length function \(l(u) \approx-\log q(u)\) for some P.M.F. \(q\). This code will be near optimal if the source distribution is \(q(u)\). However, if the true source distribution is \(p(x)\), then, \[ \begin{aligned} L-H_D(X) & \approx \mathbb{E}\left[\log_D \frac{1}{q(x)}\right]-\mathbb{E}\left[\log_D \frac{1}{p(x)}\right] \\ & =\sum_x p(x) \log_D \frac{p(x)}{q(x)} \\ & =D(p \| q) \end{aligned} \]
The relative entropy can be thought of as the cost of mismatch in lossless compression, i.e. the expected number of excess bits that will be expended due to optimizing the code for distribution \(q\) when the true distribution is \(p\).
Proof: \(L \le H_D(X) + 1\)
Recall the setup of Kraft-McMillan Inequality \(\eqrefNaN\): We wish to minimize \(L=\sum_{-} p_i l_i\) subject to the constraint that \(l_1, l_2, \ldots, l_m\) are integers and \(\sum D^{-l_i} \leq 1\).
We proved that the optimal codeword lengths can be found by finding the \(D\)-adic probability distribution closest to the distribution of \(X\) in relative entropy, that is, by finding the \(D\)-adic \(\mathbf{r}\left(r_i=D^{-l_i} / \sum_j D^{-l_j}\right)\) minimizing
//TODO \[ L-H_D=D(\mathbf{p} \| \mathbf{r})-\log \left(\sum D^{-l_i}\right) \geq 0 . \]
The choice of word lengths \(l_i=\log _D \frac{1}{p_i}\) yields \(L=H\). Since \(\log _D \frac{1}{p_i}\) may not equal an integer, we round it up to give integer word-length assignments, \[ l_i=\left\lceil\log _D \frac{1}{p_i}\right\rceil \] where \(\lceil x\rceil\) is the smallest integer \(\geq x\). These lengths satisfy the Kraft inequality since \[ \sum D^{-\left\lceil\log \frac{1}{p_i}\right\rceil} \leq \sum D^{-\log \frac{1}{p_i}}=\sum p_i=1 . \]
This choice of codeword lengths satisfies \[ \log _D \frac{1}{p_i} \leq l_i<\log _D \frac{1}{p_i}+1 . \]
Multiplying by \(p_i\) and summing over \(i\), we obtain \[ H_D(X) \leq L<H_D(X)+1 . \]
Huffman Coding
We've discussed a lot about optimal codes previously. But how can we construct an optimal code?
Here we introduce Huffman Code, which is the optimal(proved later) prefix code for a general source code distribution.
How to generate (binary) Huffman Code:
- Find 2 symbols with the smallest probability and then merge them to create a new “node” and treat it as a new symbol.
- Then merge the next 2 symbols with the smallest probability to create a new “node”. 3. Repeat steps 1 and 2 until there is only 1 symbol left.
- At the end of this process, we obtain a binary tree. The left branch of the Hoffman tree is given the bit value 0 and the right branch is given the bit value 1. The Hoffman encoding of each character is formed by taking the path from the root node to each leaf node.
Recall that this is a prefix code since we only assign the source symbols to the leaf nodes. Also note that the Huffman code is not necessarily unique since it depends on the order of the merge operations
Aside: (Source arity nomenclature):
- binary (2 symbols),
- ternary (3 symbols),
- quaternary (4 symbols),
- quinary (5 symbols),
- senary (6 symbols),
- septenary (7 symbols),
- octal (8 symbols),
- nonary (9 symbols),
- dec- imal (10 symbols)
- ...
Example
Consider a random variable X taking values in the set \(X = \{1, 2, 3, 4, 5\}\) with probabilities 0.25, 0.25, 0.2, 0.15, 0.15, respectively.
The Huffman coding is:
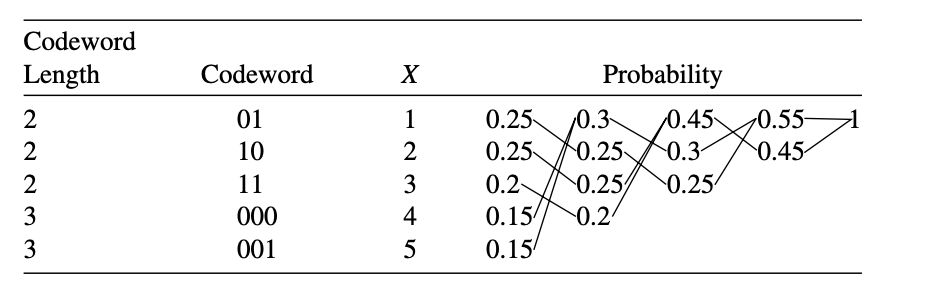
This code has average length 2.3 bits.
Optimality Of Huffman Coding
Theorem: Huffman coding is optimal; that is, if \(C^{*}\) is a Huffman code and \(C^{\prime}\) is any other uniquely decodable code, \(L\left(C^{*}\right) \leq L\left(C^{\prime}\right)\) .
In the following we'll proved the theorem for a binary alphabet, the proof can be extended for a D-ary alphabet as well.
It is important to remember that there are many optimal codes: inverting all the bits or exchanging two codewords of the same length will give another optimal code. The Huffman procedure constructs one such optimal code.
To prove the optimality of Huffman codes, we first prove some properties of a particular optimal code.
Without loss of generality, we will assume that the probability masses are ordered, so that \(p_1 \geq p_2 \geq \cdots \geq p_m\). Recall that a code is optimal if \(\sum p_i l_i\) is minimal.
Lemma
For any distribution, there exists an optimal instantaneous code (with minimum expected length) that satisfies the following properties:
- The lengths are ordered inversely with the probabilities (i.e., if \(p_j>\) \(p_k\), then \(l_j \leq l_k\) ).
- The two longest codewords have the same length.
- Two of the longest codewords differ only in the last bit and correspond to the two least likely symbols.
Proof: The proof amounts to swapping, trimming, and rearranging, as shown in Figure 5.3. Consider an optimal code \(C_m\) : - If \(p_j>p_k\), then \(l_j \leq l_k\). Here we swap codewords. Consider \(C_m^{\prime}\), with the codewords \(j\) and \(k\) of \(C_m\) interchanged. Then
\[ \begin{aligned} L\left(C_m^{\prime}\right)-L\left(C_m\right) & =\sum p_i l_i^{\prime}-\sum p_i l_i \\ & =p_j l_k+p_k l_j-p_j l_j-p_k l_k \\ & =\left(p_j-p_k\right)\left(l_k-l_j\right) . \end{aligned} \]
But \(p_j-p_k>0\), and since \(C_m\) is optimal, \(L\left(C_m^{\prime}\right)-L\left(C_m\right) \geq 0\). Hence, we must have \(l_k \geq l_j\). Thus, \(C_m\) itself satisfies property 1 . - The two longest codewords are of the same length. Here we trim the codewords. If the two longest codewords are not of the same length, one can delete the last bit of the longer one, preserving the prefix property and achieving lower expected codeword length. Hence, the two longest codewords must have the same length. By property 1 , the longest codewords must belong to the least probable source symbols. - The two longest codewords differ only in the last bit and correspond to the two least likely symbols. Not all optimal codes satisfy this property, but by rearranging, we can find an optimal code that does. If there is a maximal-length codeword without a sibling, we can delete the last bit of the codeword and still satisfy the prefix property. This reduces the average codeword length and contradicts the optimality of the code. Hence, every maximal-length codeword in any optimal code has a sibling. Now we can exchange the longest codewords so that the two lowest-probability source symbols are associated with two siblings on the tree. This does not change the expected length, \(\sum p_i l_i\). Thus, the codewords for the two lowest-probability source symbols have maximal length and agree in all but the last bit.
Summarizing, we have shown that if \(p_1 \geq p_2 \geq \cdots \geq p_m\), there exists an optimal code with \(l_1 \leq l_2 \leq \cdots \leq l_{m-1}=l_m\), and codewords \(C\left(x_{m-1}\right)\) and \(C\left(x_m\right)\) that differ only in the last bit.
Proof
Thus, we have shown that there exists an optimal code satisfying the properties of the lemma. We call such codes canonical codes.
For any probability mass function for an alphabet of size \(m\), \[ \mathbf{p}=\left(p_1, p_2, \ldots, p_m\right) \]
with \(p_1 \geq p_2 \geq \cdots \geq p_m\),
we define the Huffman reduction \[ \mathbf{p}^{\prime}=\left(p_1, p_2, \ldots, p_{m-2}, p_{m-1}+p_m\right) \] over an alphabet of size \(m-1\).
- Let \(C_{m-1}^*\left(\mathbf{p}^{\prime}\right)\) be an canonical optimal code for \(\mathbf{p}^{\prime}\).
- We denote the length of each codeword: \(l_1^{\prime}, l_2^{\prime}, \cdots, l_{m-1}^{\prime}\).
- The average length is \(L^*(\mathbf{p}^{\prime})\).
- Let \(C_m^*(\mathbf{p})\) be the canonical optimal code for \(\mathbf{p}\).
- We denote the length of each codeword: \(l_1^{\prime}, l_2^{\prime}, \cdots, l_{m}^{\prime}\).
- The average length is \(L^*(\mathbf{p})\).
The proof of optimality will follow from two constructions:
Step1
First, from the canonical code \(C_{m-1}^*(\mathbf{p}^{\prime})\) for \(\mathbf{p}^{\prime}\), we construct a code \(C_{m}(\mathbf{p})\) for \(\mathbf{p}\): We find the codeword in that corresponds to weight \(p_{m-1}+p_m\) and extend it by:
- adding a 0 to form a codeword for symbol \(m-1\)
- adding a 1 to form a codeword for symbol \(m\).
The length of each codeword of \(C_{m}(\mathbf{p})\) are: \[ l_1, l_2, \cdots, l_{m-2}, l_{m-1}, l_{m} = l_1^{\prime}, l_2^{\prime}, \cdots, l_{m-2}^{\prime}, l_{m-1}^{\prime}+1, l_{m-1}^{\prime} + 1 \] The code construction is illustrated as follows:
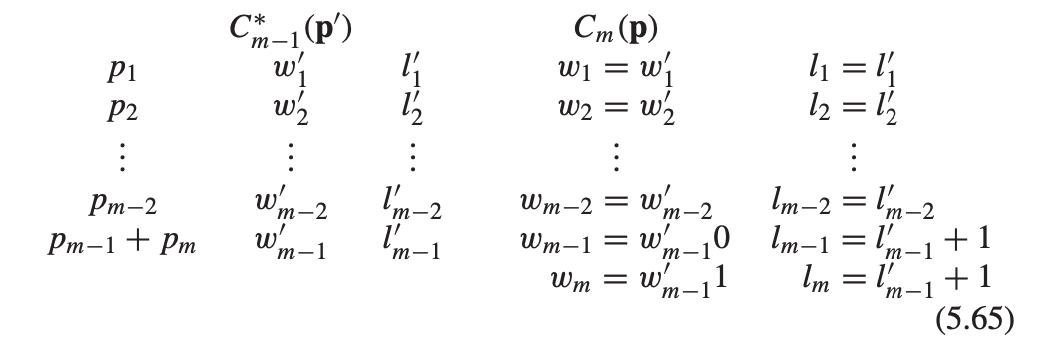
The average length of \(C_{m}(\mathbf{p})\) is \[ \begin{align} L(\mathbf{p}) & = \sum_{i=1}^{m} p_i l_i \nonumber \\ & = \sum_{i=1}^{m-2} p_i l_i+p_{m-1}\left(l_{m-1}\right)+p_m\left(l_m\right) \nonumber \\ & = \sum_{i=1}^{m-2} p_i l_{i}^{\prime} + p_{m-1} (l_{m-1}^{\prime} + 1) +p_m (l_{m-1}^{\prime} + 1 ) \nonumber \\ & = \sum_{i=1}^{m} p_i l_{i}^{\prime} + p_{m-1}+p_m \nonumber \\ & = L^*\left(\mathbf{p}^{\prime}\right)+p_{m-1}+p_m \label{eq_6.1}. \end{align} \]
Step2
Similarly, from the canonical code \(C_{m}^*(\mathbf{p})\) for \(\mathbf{p}\), we construct a code \(C_{m-1}(\mathbf{p}^{\prime})\) for \(\mathbf{p}^{\prime}\): we use Huffman reduction to merge the codewords for the two lowest-probability symbols \(m-1\) and \(m\) with probabilities \(p_{m-1}\) and \(p_m\), which are siblings by the properties of the canonical code.
The average length of \(C_{m-1}(\mathbf{p}^{\prime})\) is \[ \begin{align} L\left(\mathbf{p}^{\prime}\right) & =\sum_{i=1}^{m-2} p_i l_i+p_{m-1}\left(l_{m-1}-1\right)+p_m\left(l_m-1\right) \nonumber \\ & =\sum_{i=1}^m p_i l_i-p_{m-1}-p_m \nonumber \\ & =L^*(\mathbf{p})-p_{m-1}-p_m \label{eq_6.2} . \end{align} \]
Step3
Adding \(\eqref{eq_6.1}\) and \(\eqref{eq_6.2}\) together, we obtain \[ L\left(\mathbf{p}^{\prime}\right)+L(\mathbf{p})=L^*\left(\mathbf{p}^{\prime}\right)+L^*(\mathbf{p}) \] or \[ \left(L\left(\mathbf{p}^{\prime}\right)-L^*\left(\mathbf{p}^{\prime}\right)\right)+\left(L(\mathbf{p})-L^*(\mathbf{p})\right)=0 . \]
We know that \(L^{*}(\mathbf{p})\), \(L^{*}(\mathbf{p}^{\prime})\) are the optimal length for \(\mathbf{p}\), \(\mathbf{p}^{\prime}\). So we have:
- \(L(\mathbf{p})-L^{*}(\mathbf{p}) \geq 0\).
- \(L\left(\mathbf{p}^{\prime}\right)-L^{*}\left(\mathbf{p}^{\prime}\right) \geq 0\).
If the sum of two nonnegative terms is 0, then both of them are 0, which implies that \(L(\mathbf{p})=L^{*}(\mathbf{p})\) (i.e., the extension of the optimal code for \(\mathbf{p}^{\prime}\) is optimal for \(\mathbf{p}\)) .
Conclustion
Consequently, if we start with an optimal code for \(\mathbf{p}^{\prime}\) with \(m-1\) symbols and construct a code for \(m\) symbols by extending the codeword corresponding to \(p_{m-1}+p_{m}\) , the new code is also optimal.
But how to start with an optimal code?
Well, we can start with a code for two elements, in which case the optimal code is obvious, we can by induction extend this result to prove the following theorem.