Computer Memory Error Correction
Outline:
- Intro
- Error Correction
- Odd-Even Check
- Hamming Code
- Cyclic Redundancy Check
Intro
A semiconductor memory system is subject to errors. These can be categorized as hard failures and soft errors.
- A hard failure is a permanent physical defect. 受影响的存储单元不能可靠地存储数据.
- can be caused by harsh environmental abuse, manufacturing defects, and wear.
- A soft error is a random, nondestructive event. 它改变了某个或某些存储单元的内容, 但没有损坏机器
- can be caused by power supply problems or alpha particles.
- These particles result from radioactive decay and are distressingly common because radioactive nuclei are found in small quantities in nearly all materials.
- can be caused by power supply problems or alpha particles.
Both hard and soft errors are clearly undesirable, and most modern main memory systems include logic for both detecting and correcting errors.
Error Correction
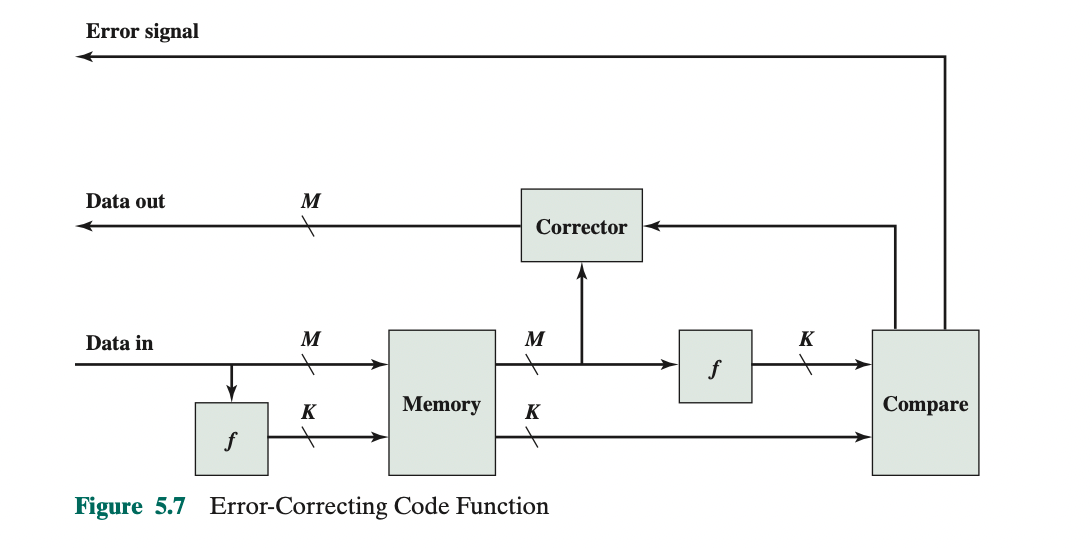
Error Correction的基本思想就是使用额外的checkbit.
Steps:
记输入的数据为 \(D\) , 有 \(M\) 位. 我们使用函数 \(f\) 将其编码为 \(K\) 位 checkcode, 记为 \(C\). The actual size of the stored word is $ M + K $ bits
接收方收到 \(M + K\) bits 数据, 其中的 \(M\) 位数据记为 \(D'\) , \(K\) 位checkcode记为 \(C'\) .
对 \(D'\) 再次使用 \(f\) 得到 \(K\) 位的 \(C''\).
将 \(C'\) 和 \(C''\) 做比较( 事实上就是异或 ), 得到故障字(syndrome word) \(S\) : \[ S = C' \oplus C'' \]
- No errors are detected. 使用数据 \(D'\)
- An error is detected, and it is possible to correct the error. 使用 \(D'\) 来生成正确的数据 \(D''\) , 并使用 \(D''\)
- An error is detected, but it is not possible to correct it. This condition is reported.
Odd-Even Check
最简单的方法是奇偶校验.
为了方便说明, 我们用“奇偶性”来代指\(D\)所含有的1的个数是奇数还是偶数. 并定义比特串\(D\)的奇偶性为\(f(D)\).
- 当\(1\)的个数为奇数时, \(f(D)=1\), 反之为\(0\).
定义1位checkbit \(C\) , \(C = f(D)\)
假设数据为\(𝐷=𝐷_M \cdots 𝐷_2𝐷_1\):
奇校验: \[ C=D_{M} \oplus \cdots \oplus D_{2} \oplus D_{1} \oplus 1 \] 偶校验: \[ C=D_{M} \oplus \cdots \oplus D_{2} \oplus D_{1} \]
奇偶校验的区别仅仅是\(C = f(D)\)的计算方式不同.
Steps
以偶校验为例:
发送方计算\(C = f(D)\). 将 \(C\) 与 \(D\) 一同发送
接收方收到\(C'\) 和 \(D'\), 计算 \(C'' = f(D')\) : \[ C''=D'_{M} \oplus \cdots \oplus D'_{2} \oplus D'_{1} \]
- 如果是奇校验, 则\(C''=D'_{M} \oplus \cdots \oplus D'_{2} \oplus D'_{1} \oplus 1\)
计算\(S\) \[ S = C' \oplus C'' \]
Error Detection
\[ S = C' \oplus C'' \]
已知\(C = f(D), C'' = f(D')\). 现在根据 \(C\), \(D\)在传输过程中的出错情况进行分类讨论:
- \(D\):
- 如果\(D\)在传输过程中没有出错, 则$D’ = D, C’’ = f(D’) = f(D) $;
- 如果\(D\)在传输过程中出错了, 但出错位数为偶数位, 则\(C'' = f(D') = f(D)\)
- 如果\(D\)在传输过程中出错了, 且出错位数为奇数位, 则\(C'' = f(D') = \neg f(D)\)
- \(C\): 注意到\(C\)仅有1位
- 如果\(C\)在传输过程中没有出错, 则\(C' = C, C' = C = f(D)\)
- 如果\(C\)在传输过程中出错了, 则\(C' = \neg C = \neg f(D)\)
也就是说:
- 如果\(D\)在传输过程中没有出错, 或仅仅出错了偶数位, 则\(C'' = f(D)\). 否则\(C'' = \neg f(D)\)
- 如果\(C\)在传输过程中没有出错, 则\(C' = f(D)\). 否则\(C' = \neg f(D)\)
现在我们考虑\(S\):
\(𝑆 = 0\) : \(C' =C''\), 则:
- 要么\(C' = C'' = f(D)\), 即\(D\)没出错或仅仅出错了偶数位, 且\(C\)没出错;
- 要么\(C' = C'' = \neg f(D)\), 即\(D\)出错了奇数位, 且\(C\)也出错.
- 在这两种情况下, \(C+D\) 要么没出错, 要么只出错了偶数位
- \(+\)表示比特串的concataion
- 注意到\(C\)只有一位, 因此\(C\)出错(1位)且\(D\)出错奇数位时, \(C+D\) 就出错了偶数位
\(S = 1\): \(C' \ne C''\), 则\(C+D\) 出错了奇数位
Drawbacks
- 不能检测到偶数个bit出错的情况
- 发现错误后不能校正, 因为不能定位到出错的bit.
Hamming Code
The simplest of the error-correcting codes is the Hamming code devised by Richard Hamming at Bell Laboratories.
Hamming Code is a single-error-correcting (SEC) code
- 只能检测和纠正1-bit errors
Idea
见如下Venn diagram:
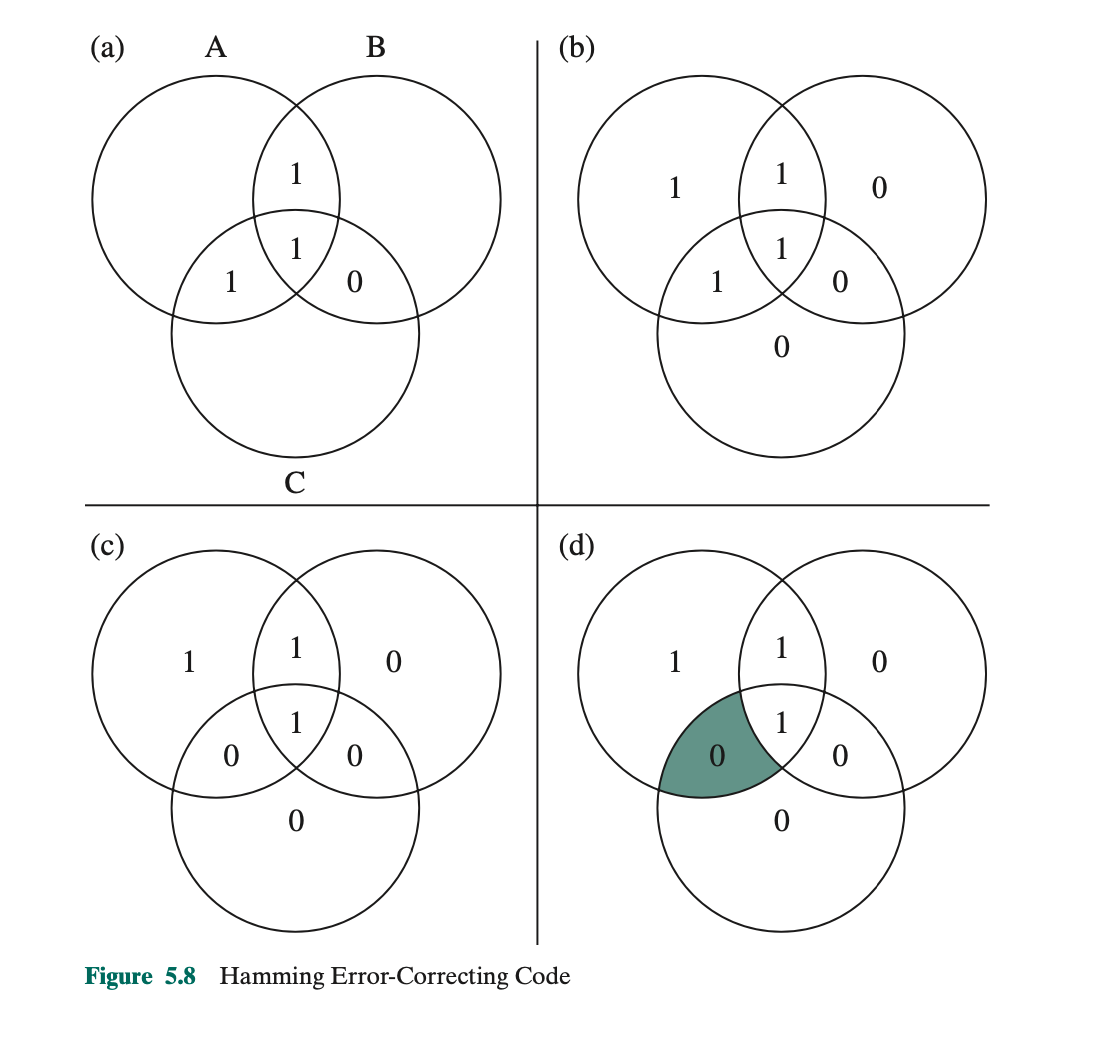
假设$ M = 4 $ :
- 我们画三个圆, 中间相交的四个部分分别填4 data bits ( 如图a ).
- 剩下的最外面三个部分填 parity bits ( 也就是checkcode ). Each parity bit is chosen so that the total number of 1s in its circle is even( 如图b )
- Now, if an error changes one of the data bits ( 如图c ), it is easily found.
- By checking the parity bits, discrepancies are found in circle A and circle C but not in circle B. Only one of the seven compartments is in A and C but not B ( 如图d ). The error can therefore be corrected by changing that bit.
Steps
- 将数据分成几组, 对每一组都使用奇偶校验. 我们默认使用偶校验
- 数据输入: 为数据 \(D\) 中的每组都生成checkbit, 合并得到 \(K\) 位check code \(C\)
- 数据输出: 为数据 \(D'\) 中的每组都生成checkbit, 合并得到 \(K\) 位check code \(C''\)
- 检错:将 \(C''\) 和取出的 \(C’\) 按位进行异或, 生成 $K $位 syndrome word \(S\). 对\(S\)分类讨论:
- 全部是0:没有检测到错误
- 有且仅有1位是1:错误发生在校验码中的某一位,不需要纠正
- 有多位为1:错误发生在数据中的某一位,将𝐷′中对应数据位 取反即可纠正(得到𝐷")
Check Code Length
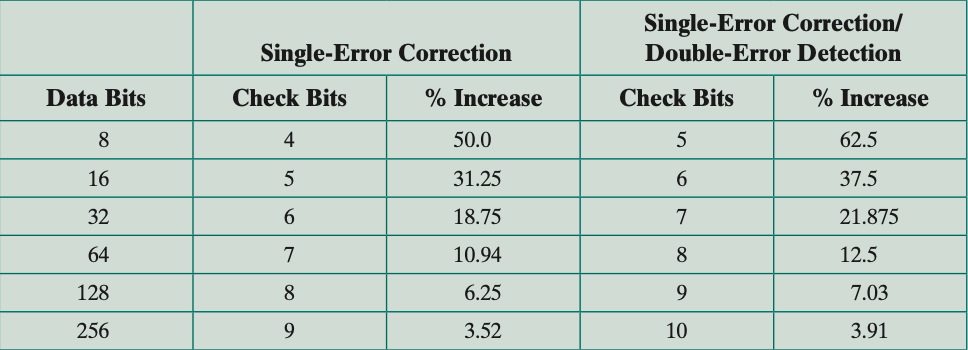
- 从上表可以看到, 使用checkcode会使得实际可用的主存( 用户可见的主存 ) 比 事实上的主存 大小更小. 对于64-bit的内存, 如果使用7bit的hamming code, 它的实际word-size是 64 + 7 = 71bit, 而用户只能看见其中的64bit.
假设最多1位发生错误, 可能的情况有:
- \(D\) 中有1位出现错误: 有 \(M\) 种情况
- \(C\) 中有1位出现错误: 有 \(K\) 种情况
- 没有错误: 有 \(1\) 种情况
因此, \(K\) 位的\(S\) 需要能表示 \(M + K + 1\) 种情况, 即满足: \[ 2^{K}-1 \geq M+K \] E.g. for a word of 8 data bits ( \(M = 8\) ), we have
- \(K=3: 2^{3}-1<8+3\)
- \(K=4: 2^{4}-1>8+4\)
因此, \(M=8\) 时 \(K=4\)
Checkbit
假设\(M=8, K=4\). 则数据最终被表示为12bit. 下表中的Position number是这12位中每个bit的的位置(十进制)的二进制表示.

checkbit的position number是2的幂:
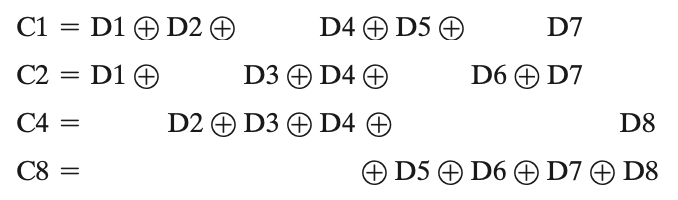
- \(\mathrm{C}1\): 0001
- \(\mathrm{C}2\): 0010
- \(\mathrm{C}4\): 0100
- \(\mathrm{C}8\): 1000
- …
Each check bit operates on every data bit whose position number contains a 1 in the same bit position as the position number of that check bit.
比如说, \(\mathrm{C}1\) 是 \(0001\) , 因此\(\mathrm{C}1\) 就和所有的 position number 的第一位为 \(1\) 的 databit 有关, 即data bit positions 3, 5, 7, 9 and 11 (D1, D2, D4, D5, D7)
- bit positions 3, 6, 7, 10, and 11 all contain a 1 in the second bit position, as does C2;
![checkbit cal]()
Looked at another way, bit position n is checked by those bits \(C_i\) such that \[ n=\sum_{i=1}^{K} (C_{i}) \] For example, position 7 is checked by bits in position 4, 2, and 1; and 7 = 4 + 2 + 1.
Example
Let us verify that this scheme works with an example. Assume that the 8-bit input word is \(00111001\), with data bit \(\mathrm{D}1\) in the rightmost position. The calculations are as follows:
Sender: Compute \(C\) :
![checkbit exp step1]()
假设 \(\mathrm{D}3\) 出错, 从0变成了1. 接收方收到 \(D'\) and \(C'\), then Compute \(C''\) :
![checkbit exp step2]()
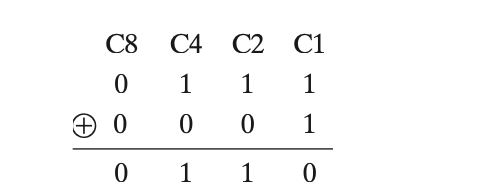
最后计算故障字\(S\): \[ S = C' \oplus C'' \]
![checkbit exp step3]()
得到\(0110 = 3\), 发现是\(\mathrm{D}3\) 出错
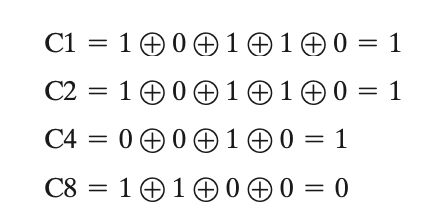
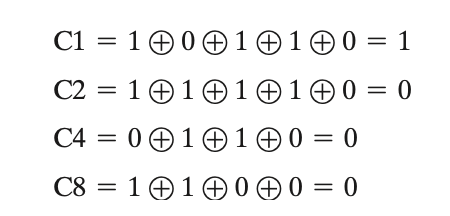
Why Only One-Bit Errors?
In computer operation 2-bit errors are very, very unlikely.
假设: the probability of a 1-bit error = \(10^{-9}\) , if a computer makes 10,000,000 moves a second
On average you get an error every 100 seconds = less than 2 minutes.
相对应的, 2-bit error的概率大概是 \(10^{-18}\), 使用同样的电脑, you get a 2-bit error once every 1011 seconds = once every 3,171 years.
There may be other considerations, specifically to do with data communications. It is quite common to establish communications over noisy lines, for example, and then the probability of errors increase dramatically. It often happens that there is a short period when may be multiple-bit errors, and it would be impracticable to use a Hamming code in this situation. Other schemes more appropriate to this problem are used instead.
SEC-DED
Hamming Code只能检查和纠正1-bit error. More commonly, semiconductor memory is equipped with a single-error-correcting, double-error-detecting (SEC-DED) code. 这通过添加一个额外的checkbit完成
- 单纠错, 双检错. ( 可以找到两个位产生的错误, 并纠正一个位的错误 )
Idea
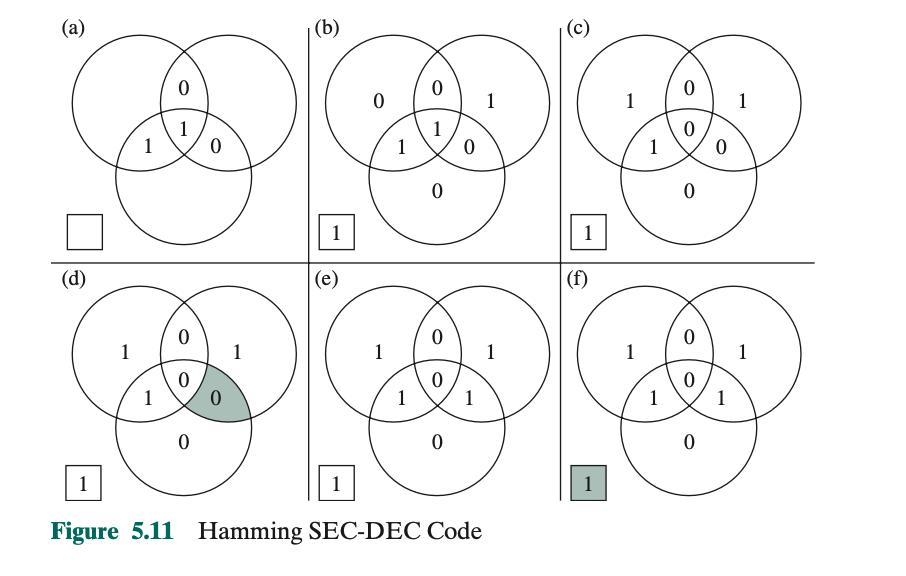
This figure illustrates how such a code works, again with a 4-bit data word.
- If two errors occur ( 如图c )
- The checking procedure goes astray ( 如图d )
- The situation worsens the problem by creating a third error ( 如图e )
- To overcome the problem, an eighth bit is added that is set so that the total number of 1s in the diagram is even. The extra parity bit catches the error (f).
Steps
添加: \[ C_{5}=D_{1} \oplus D_{2} \oplus D_{3} \oplus D_{5} \oplus D_{6} \oplus D_{8} \]
SED-DED的故障字 \(S\) 的分析:
- 都是0: 没有检测到错误
- 1位为1: 在5个校验位中有一个发生了错误, 不需要修正
- 2位为1: 有2位数据和校验位出现错误,但找不到错误的位置
- 3位为1: 8位数据位中有1位发生了错误,该错误可以被纠正
- 3位以上均为1: 严重情况,检查硬件
Drawbacks
- Hamming Code需要额外的存储空间
- Hamming Code需要先对数据进行分组, 这无法处理流式数据
Cyclic Redundancy Check
循环冗余校验(Cyclic Redundancy Check, CRC)
- 适用于以流格式存储和传输大量数据
- 用数学函数生成数据和校验码之间的关系
Steps
- Get Check Code:
- 假设数据有 \(M\) 位,左移数据 \(K\) 位(右侧补0), 并用 \(K+1\) 位生成多项式除它(模2运算)
- 模2除法与算术除法类似,但每一位除的结果不影响其它位,即不向上一位借位,所以实际上就是异或
- 采用 \(K\) 位余数作为checkcode
- 把checkcode放在数据(不含补的0 )后面, 一同存储或传输
- 假设数据有 \(M\) 位,左移数据 \(K\) 位(右侧补0), 并用 \(K+1\) 位生成多项式除它(模2运算)
- 校错: 如果M+K位内容可以被生成多项式除尽,则没有检测到错误 • 否则,发生错误
Example
假设数据是 \(100011\), 生成多项式为\(x^3 + 1\) ( 二进制表示为\(1001\) ):
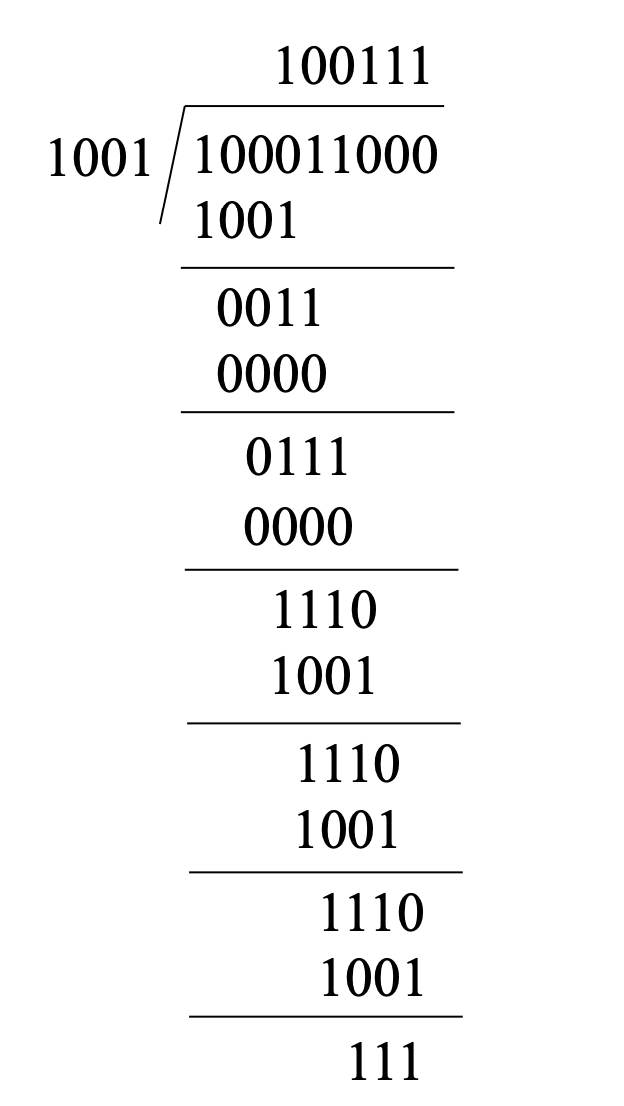
最后生成的checkcode是\(111\)