Lexical Analysis
Outline:
- Intro
- Language
- Pattern
- Token
Intro
lexical analysis: 词法分析器( Lexical Analyser, or Scanner )将源程序按字符流读入, 按照模式匹配映射成一个个 lexeme( 词素 ), 再将lexeme转化成如下形式的token( 词法单元 ):
< token-name, attribute-value >
- 当一串字符能模式匹配多个词素时, 必须通过属性来传递附加的信息。
- token-name 表示某种词法单位的抽象符号. 语法分析器通过token-name即可确定token sequence的结构
- attribute-value 指向符号表的一项, 用于语义分析和代码生成
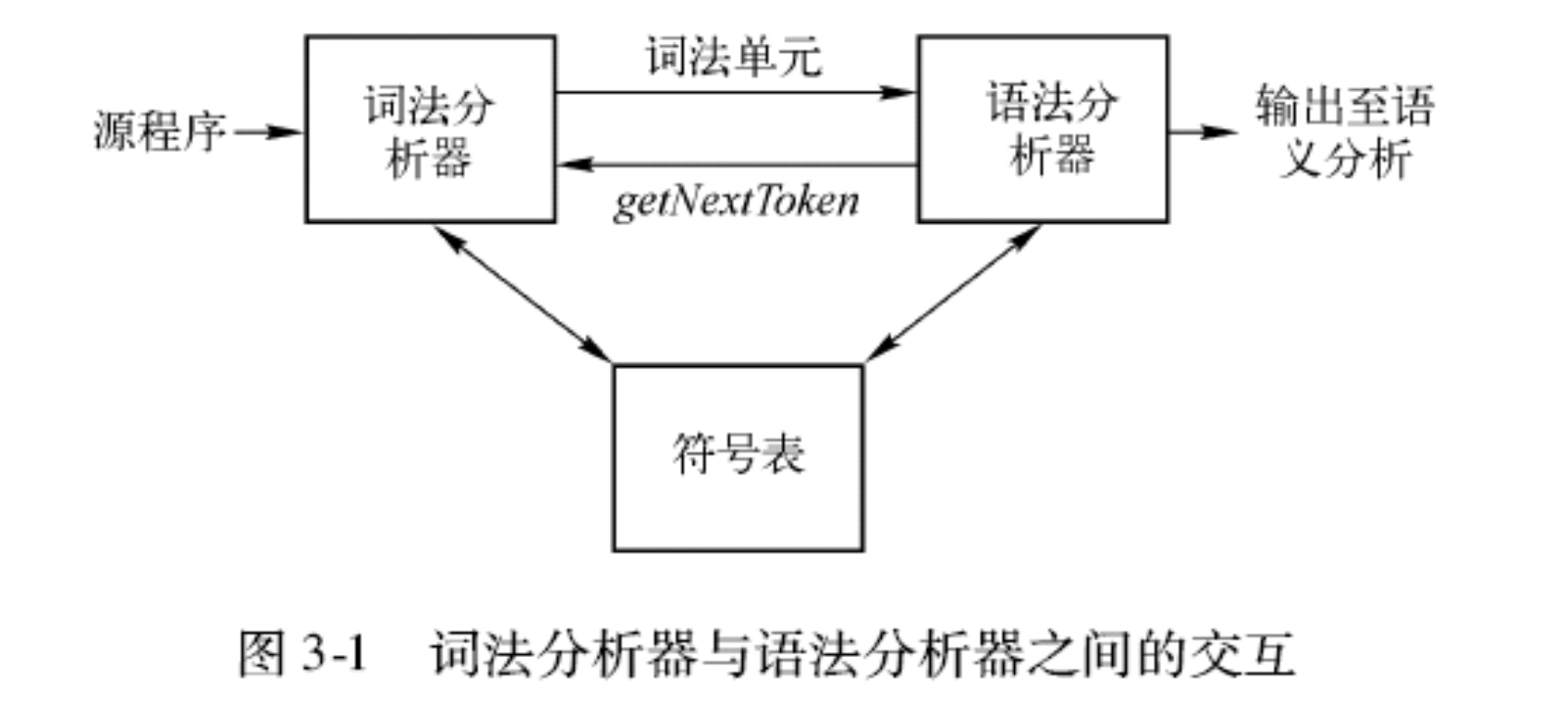
Scanner由Parser调用, 需要的时候不断读取读入并生成Token
![Interaction with Parser]()
Language
字母表: 一个有限的符号集合
- 二进制 {0, 1}
- ASCII
- Unicode
- 典型的字母表包括字母、数位和标点符号
串: 字母表中符号组成的一个有穷序列
\(|s|\): 串s的长度
\(\epsilon\): 长度为0的串, 空串
语言:给定字母表上一个任意的可数的串的集合.
- 语法正确的C程序的集合, 英语, 汉语
和串有关的术语(banana)
- 前缀: 从串的尾部删除0个或多个符号后得到的串 (ban、banana、 ε)
- 后缀: 从串的开始处删除0个或多个符号后得到的串 (nana、banana、ε)
- 子串: 删除串的某个前缀和某个后缀得到的串 (banana、nan、 ε)
- 真前缀, 真后缀, 真子串:既不等于原串,也不等于空 串的前缀、后缀、子串
- 子序列: 从原串中删除0个或者多个符号后得到的串 (baan)
串的运算:
- 连接(concatenation): x和y的连接的就是把y附加到x的后面形成的串, 记作xy
- x=dog, y=house, xy=doghouse
- 指数运算(幂运算): \(s_0=\epsilon\) , \(s_1=s\) , \(s_i=s^{i-1}s\)
- \(x\)=dog , \(x^0\)=ε , \(x^1\)=dog , \(x^3\)=dogdogdog
- 连接(concatenation): x和y的连接的就是把y附加到x的后面形成的串, 记作xy
语言上的运算:
Operation Def L和M的并 \(L \cup M = \{ s \ | \ s \ \in \ L \ \mbox{or} \ s \in M \}\) L和M的连接 \(LM = \{st \ | \ s \in L \ \mbox{and} \ t \in M \}\) L的Kleene闭包 \(L^* = \cup_{i=0}^\infty L^i\) L的正闭包 \(L^+ = \cup_{i=1}^\infty L^i\)
Pattern
- Parser对输入的字符串进行模式匹配, 得到lexeme
- 模式( Pattern )可以用正则表达式( Regular Expression )来表示.
- 面对复杂的语言时, 正则也会变得极其复杂, 为此可以用NFA或DFA来表示模式.
- 可以证明, 正则, NFA, DFA是等价的, 可以相互转换
保留字和标识符的识别
在很多程序设计语言中,保留字也符合标识符的模式, 识别标识符的状态转换图也会识别保留字.
解决方法:
- 在符号表中预先填写保留字,并指明它们不是普通标识符
- 为关键字/保留字建立单独的状态转换图. 并设定保留字的优先级高于标识符
Token
| Token | Description | Lexeme Example |
|---|---|---|
| if | 字符i, f | if |
| else | 字符e, l, s, e | else |
| comparison | <, >, <=, !=等比较运算符 | <=, != |
| id | 字母开头的字母/数字串 | Po, score, D2 |
| number | 任何数字常量 | 3.1415, 0, 6.02e42 |
| literal | 在""之间, 除""以外的任何字符 |
"core dumped" |
Example
字符串E = M * C ** 2对应的Token:
<id, 指向符号表中E的条目的指针><assign_op><id, 指向符号表中M的条目的指针><mult_op><id, 指向符号表中C的条目的指针><exp_op><number, 整数值2>