Compilers Basic
Outline:
- Language Processors
- Example: GCC
- Phases Overview
- Front End
- Optimizer
- Back End
- Others
Language Processors
All roads lead to the CPU:
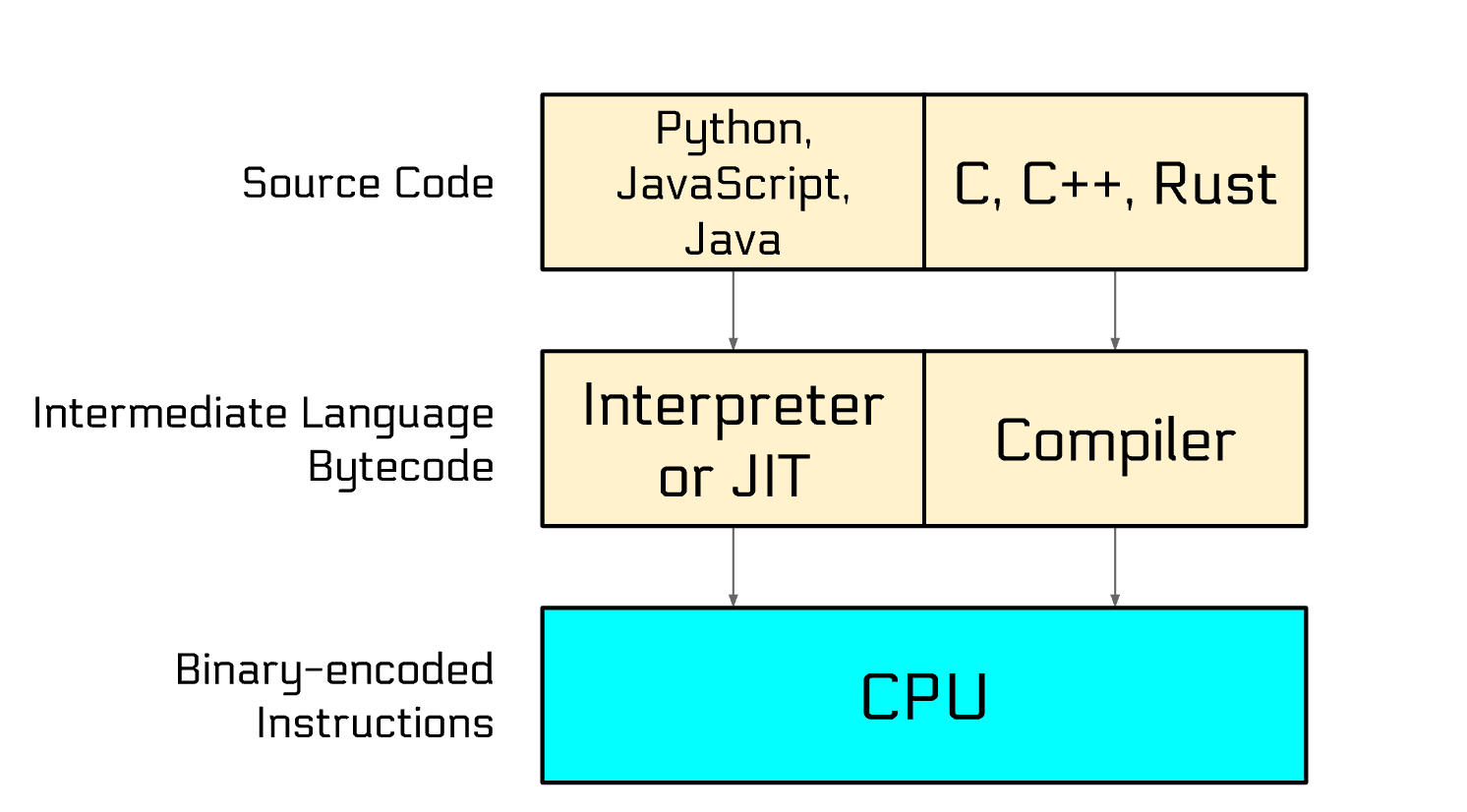
Compiler

- compiler maps a source program into a semantically equivalent target program
- 整个编译过程可以看成 a sequence of phases, 每个phase将源程序的一种表示转换成另一种表示, 程序的中间表示称为IR( Intermediate representation ). phrases大致分两个:
- Analysis: 解析源程序, 得到语法树, 根据语法树创建IR, 并收集源程序的信息存入symbol table, 与IR一起传入 synthesis part
- 可分为: Lexical Analysis, Syntax Analysis, Semantic Analysis
- Synthesis: 根据中间表示和符号表创建目标代码
- Analysis: 解析源程序, 得到语法树, 根据语法树创建IR, 并收集源程序的信息存入symbol table, 与IR一起传入 synthesis part
- 我们定义phases的组合为“pass”, 也就是说, 编译器一共要经过3个pass:
- Frontend pass: 编译器的Analysis部分, 根据源代码生成IR
- Optimization: The optimizer is an ir-to-ir transformer that tries to improve the ir program in some way.
- Backend pass: 编译器的Synthesis部分, 根据IR生成目标代码.
- 如果target language是machine language, 那么用户可以在机器上直接执行target program. 从source program生成machine language的典型过程:

Structure

Interpreter
解释器不会将一种语言翻译为另一种, 而是直接根据 source language 执行

- 相比机器执行, 解释器执行起来效率更低, 但是更易于debug
Hybrid

- Java的language processor结合了compiler和interpreter. Java program首先被编译为统一格式的bytecode作为target program, 后者再被放入JVM解释执行.
- 为了提高速度, 有的Java Compiler采用了JIT( just-in-time ), 在编译时不仅生成字节码, 还把字节码编译为机器码, 然后直接运行机器码的程序.
- 无论是将bytecode解释执行, 还是将其编译为机器吗执行, 都需要“dynamic cimpilation”
- Java is not the first language to employ such a mix. Lisp systems have long included both native-code compilers and virtual-machine implementation schemes [266, 324]. The Smalltalk-80 system used a bytecode distribution and a virtual machine [233]; several implementations added just-in-time compilers [126].
Example: GCC
以GCC处理C程序的过程为例:

- Preprocessor: source program \(\rightarrow\) modified source program
- gcc的预处理器
cpp将.c,.h文件变成.i文件
- gcc的预处理器
- Compiler: \(\rightarrow\) target assembly program
- GCC的编译器是
cc1, 它把.i文件编译成汇编语言的.s文件。
- GCC的编译器是
- Assembler: \(\rightarrow\) relocatable machine code
- GCC的汇编器是
as, 它把汇编文件汇编成机器指令文件,并打包成"可重定向文件", 这是个二进制文件,后缀为.o
- GCC的汇编器是
- Linker/Loader: \(\rightarrow\) target machine code
- GCC的汇编器是
ld, 它将上一阶段生成的可重定向文件和系统内已存在的可重定向文件,形成最终的可执行目标文件( executable object file )并被loader加载入内存 - 被链接的可重定向文件包括
.o文件, 也包括静态库.a和动态库.so)链接起来( 在此期间会将相对地址解析为绝对地址 )
- GCC的汇编器是
在windows中, 可重定向文件后缀为obj, 可执行目标文件后缀为exe
Phases Overview
Symbol Table被所有phase使用

- Lexical Analyzer: character stream \(\rightarrow\) token stream
- Syntax Analyzer: \(\rightarrow\) syntax tree
- Semantic Analyzer:\(\rightarrow\) syntax tree
- Intermediate Code Generator:\(\rightarrow\) intermediate representation
- Machine-Independent Code Optimizer: \(\rightarrow\) intermediate representation
- Code Generator: \(\rightarrow\) target-machine code
- Machine-Dependent Code Optimizer: \(\rightarrow\) target-machine code
Example

Front End
The front end determines if the input code is well formed, in terms of lexicality, syntax and semantics.
- 我们规定: 语法 = 词法+句法, 即 grammer = lexicality + syntax. 由scanner和parser完成grammer的分析.
- Front ends rely on results from formal language theory and type theory
如果语法和语义都正确, 前端就会生成IR.
以句子“Compilers are engineered objects.” 为例:
Lexical Analysis
- Lexical Analysis( aka scanning ): 找出词法单元, 并赋予其词性( a part of speech ). 最后生成的词法单元形式为(p,s), where p is the word’s part of speech and s is its spelling.

Syntax Analysis
Syntax Analysis( aka parsing ): 根据给出的语法规则( rule ), 得到derivation:
rules:
![rules]()
derivation:
![derivation]()
可以看到, 原句的derivation满足了给定的rules, 因此原句在语法上正确( grammatically correct )


Semantic Analysis
Semantic Analysis: 一个语法正确的句子未必是有意义的, 比如: “Rocks are green vegetables” 符合上述的语法, 但是没有意义.
程序语言的语义分析一般比较简单, 主要包括Type check, Object binding等等. Analyser使用语法树和符号表来检查源程序的语义, 使得源程序和目标程序的语义一致.
同时会收集类型信息,存入语法树或符号表,用于后续的中间代码生成.
Optimizer
Analysis
The analysis determines where the compiler can safely and profitably apply the technique.
Compilers use several kinds of analysis to support transformations:
- Data- flow analysis : reasons, at compile time, about the flow of values at runtime.
- Dependence analysis : uses number-theoretic tests to reason about the values that can beassumed by subscript expressions.
Transformation
Compiler不仅要分析IR, 还要利用分析的结果来将IR转换成更“好”的形式( 比如更快, 更节约空间, 更省电... )

Back End
根据IR来generate target-machine code
Instruction Selection
首先要将IR映射到机器指令:

- This code assumes that a, b, c, and d are located at offsets @a, @b, @c, and @d from an address contained in the register rarp.
- 这里用的汇编语言是ILOC( Intermediate Language for an Optimizing Compiler ), 是一个简化版的汇编
- Virtual register: 在Instruction Selection阶段, Compiler使用虚拟的寄存器, 而不关心机器实际的寄存器. 虚拟寄存器到物理寄存器的映射在Register Allocation完成.
Register Allocation
然后将虚拟寄存器映射到目标机器的物理寄存器. 此时还要考虑一些优化问题. 比如, 下面的例子只使用了“最少的寄存器”:

Instruction Scheduling
编译器可以对指令重拍序, 甚至删除一些指令, 来提高速度:


Interactions Among Code-Generation Components
code-genetaion时会遇到很多问题, 这些问题甚至可能是交错的. 比如, 指令重拍就会导致一些变量的依赖出现更改, 影响寄存器分配.
Others
编译器的一些其他应用:
- Binary Translation: 把平台的机器码程序翻译到另一个平台. 比如把x86机器码翻译到VLIW平台.
- Hardware Synthesis: 硬件设计使用硬件描述语言: Verilog or VHDL( Very high speed integrated circuit Language). 它们工作在 register transfer level( RTL )
- Compiled Simulation: 以前都是先有处理器再有编译器, 现在都是先有编译器, 通过模拟器来模拟一个处理器, 使用compiler来衡量该处理器的性能.( 也就是只要有架构设计就行了, 不需要硬件实现. )