OLAP
Outline:
- OLAP Database
- Columnar Database
- ETL vs ELT
OLAP Database
OLAP数据库是数据分析领域过去几十年内常用的数据仓库,近年来已经被列数据库逐步取代。
OLTP VS OLAP
- OLTP: using a database to run your business
- 对OLTP 数据库的查询形如: "one Honda Civic by Jane Doe in the London branch on the 1st of January, 2020";
- OLAP: using a database to understand your business
- 对OLAP数据库的查询形如: "give me the total sales of green Honda Civics in the UK for the past 6 months"
可以看到,OLAP的查询比OLTP复杂的多。 关系型数据库可以胜任OLTP, 但是对于每个OLTP查询,都可能要进行大量连表,效率很低。 而在BI( Bussiness Intelligence )中, 有着大量的OLAP查询
- 可以看到,每一次子查询就是查询某个"维度(dimention)"。 比如,如果要查“找出某天某地生产的所有产品”, 那么对于“时间”、“地点”、“产品”这三个维度,就要进行三次连表,开销是不可接受的
What is OLAP DataBase
OLAP 数据库把数据按维度组织成高维数组。 一组数据就形成了一个"cube", 进行OLAP查询时复杂度只有O(1)
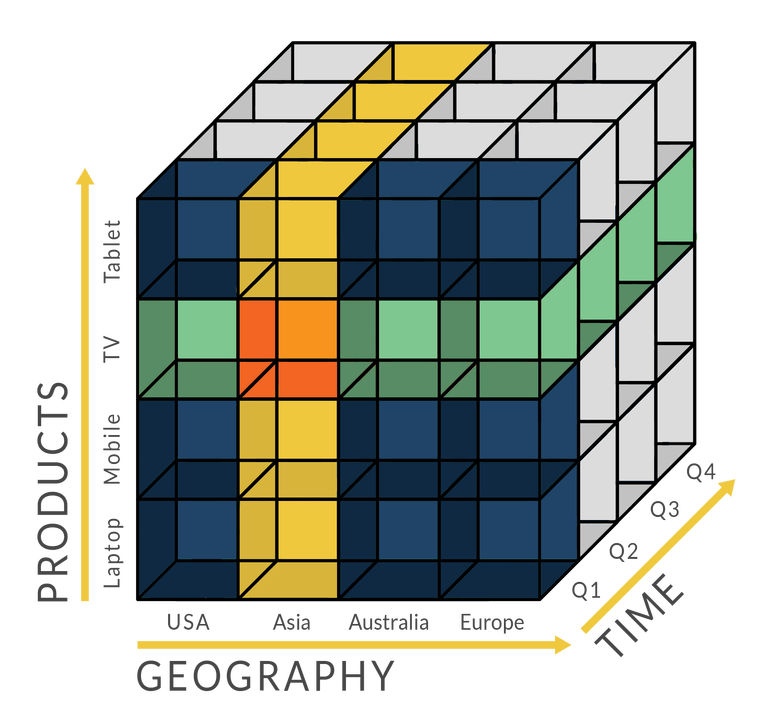
- 假如OLAP cube内存占用过大,很多OLAP数据库只会加载cube的一部分进内存,其余的放在磁盘
Problems
OLAP数据库的问题有:
- 每个cube只能适应一小部分的OLAP查询。 假如出现了新查询或者新的类型的数据,需要新建Cube. 比如说,对于上图的Cube,如果数据分析师想要进一步分析“省份”数据,而原有Cube没有“省份”这个维度,就得让数据工程师新建一个包含了这个维度的Cube
- 要把数据仓库中的数据转化为OLAP Cube, 需要对数据仓库进行一定的建模( 需要满足一些稀奇古怪的范式要求, 比如 Kimball dimensional modeling, Inmon-style entity-relationship modeling, or data vault modeling ); 并且采用大量的pipeline, 比如ETL (extract-transform-load)
- 数据分析师的工作会严重依赖数据工程师。 因为每次有新的分析,都需要数据工程师来创建新Cube。 工作效率极低。 同时数据工程师还得维护pipeline。
Fall of OLAP
OLAP Cube的问题来源于它要牺牲劳动力来节省计算和存储资源。近年来,随着CPU性能提升,内存价格降低,以及列数据库的出现, OLAP已经逐步被列数据库所取代。 列数据库可以胜任OLAP workload,并且性能更高。 这样做的好处有:
- 直接使用原数据,不做任何转化。 也就不需要那么多的pipeline和配套的工具,也不用雇那么多数据工程师了
- 既然不需要转化成OLAP Cube, 那么数据仓库设计时也不必遵循奇奇怪怪的范式
- 数据分析师不需要依赖数据工程师来创建cube了, 可以自己直接用SQL查询
Columnar Database
What is Columnar Database
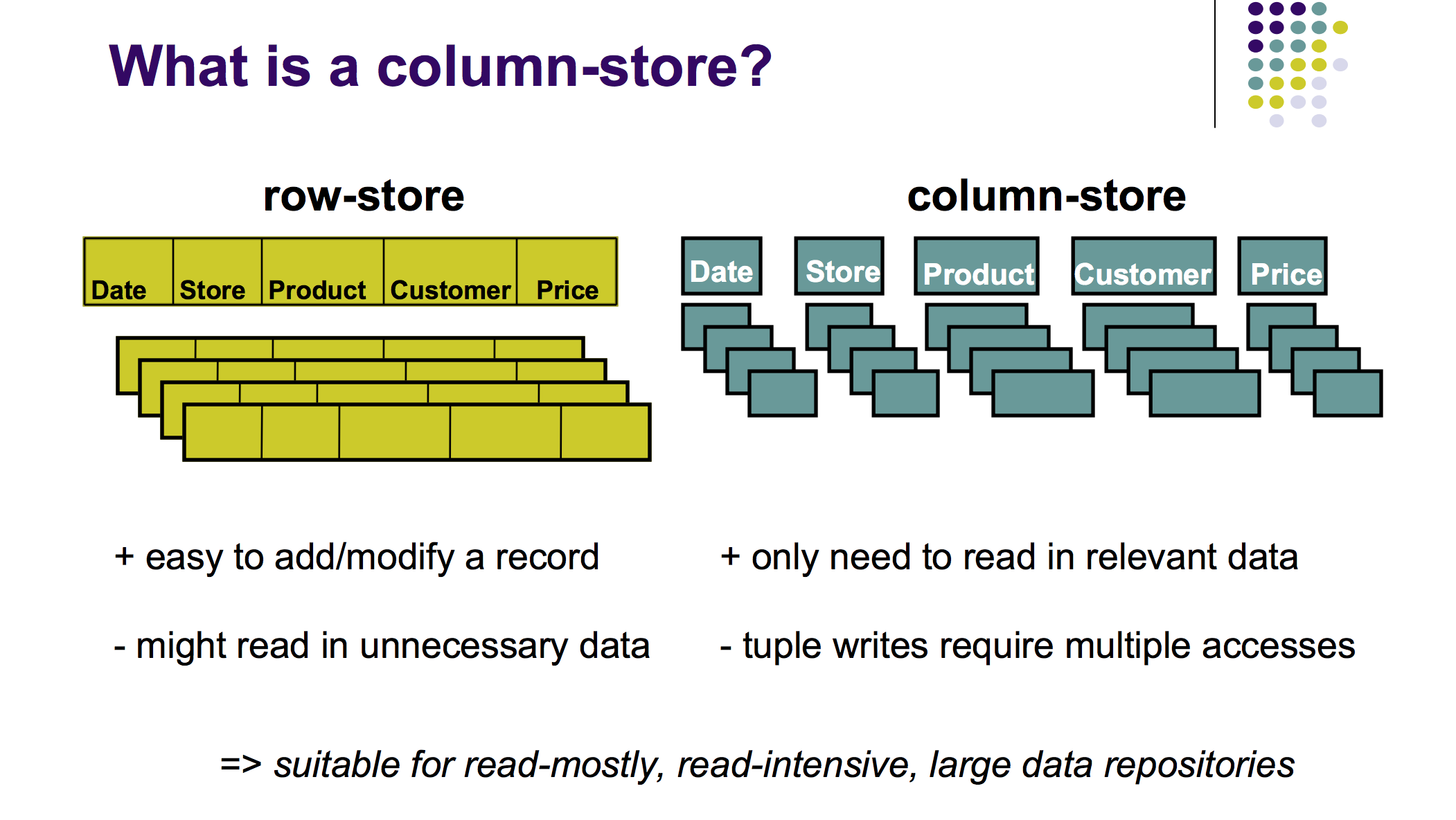
如图,列数据库把数据按列存储,特点有:
- 对于"Read only"的OLAP workload(也就是有好多维度的只读查询),这种存储方式是完美契合的,每个维度查一列就行了
- 同时也可以看到列数据库的缺点 --- 修改既有数据的效率非常低,因为要把该行的每一列进行一次删除。 好在OLAP workload大部分是Read Only的, 事实上很多OLAP查询根本就不允许修改原有数据
- 由于数据按列存储,而同一列的数据一般而言格式相似,因此列数据库比行数据库更容易压缩,减少内存占用
- 因为列数据库可以更大程度地压缩,也就能腾出更多的内存来给其他进程使用。 列数据库的排序等操作因此更快
ETL vs ELT
- ETL:Extract, Transform, and Load. 即将源数据库( OLTP database )的数据“提取( extract )”到专门的数据处理服务器, 后者将数据“转换( transform )”为符合要求的形式,最终结果被加载到最终的数据仓库( data warehouse )
- ETL和OLAP是紧密联系的。 ETL的目的数据仓库的数据已经是“提取、转换”之后的数据了。 因此ETL具有和OLAP相同的缺点:
- 每次新查询都要重新ETL
- 需要专人来进行ETL
- 最糟的是,海量数据的ETL是很耗时的。 那应该在什么时候进行ETL呢? 你可能认为可以在晚上ETL,白天工人上班的时候直接拿结果来用。 但是如果是跨国公司,某个地方的晚上是另一个地方的白天,就没法做到ETL的同步,数据也就没法同步
- ETL和OLAP是紧密联系的。 ETL的目的数据仓库的数据已经是“提取、转换”之后的数据了。 因此ETL具有和OLAP相同的缺点:
- ELT: Extract, Load, and Transform. 随着硬件的发展,现在普遍将数据直接传输到目标数据仓库,然后数据分析师手动进行数据处理( Transform )