OS Persistence
Outline:
- I/O Devices
- File
- File System
- Locality and FFS
- Crush-Consistency Problem
Ref: OSTEP
I/O Devicecs
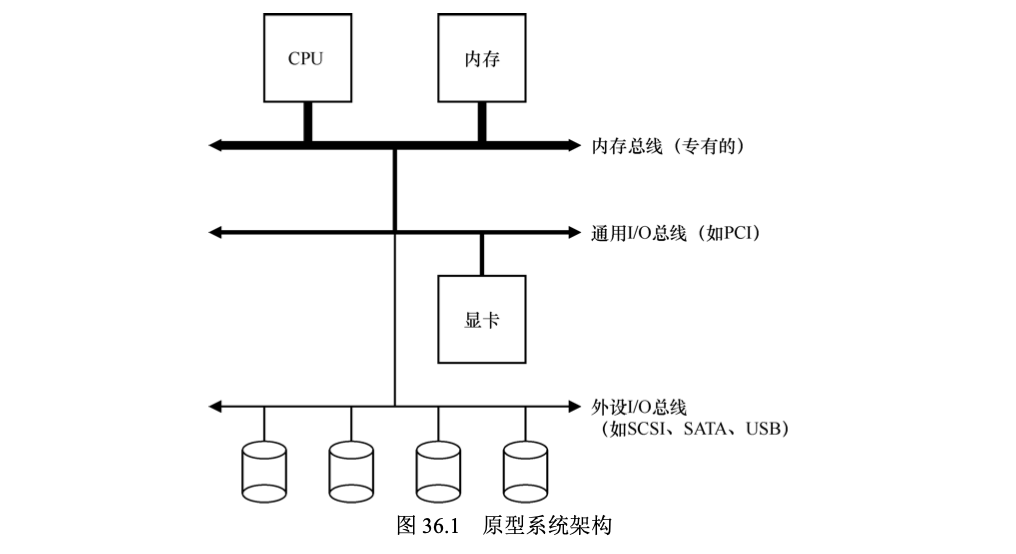
- CPU通过内存总线连接到内存
- 图像和其他高性能IO设备连接到常规的IO总线(如PCI)
- 最慢的设备,如键盘、鼠标等,连接到外围总线
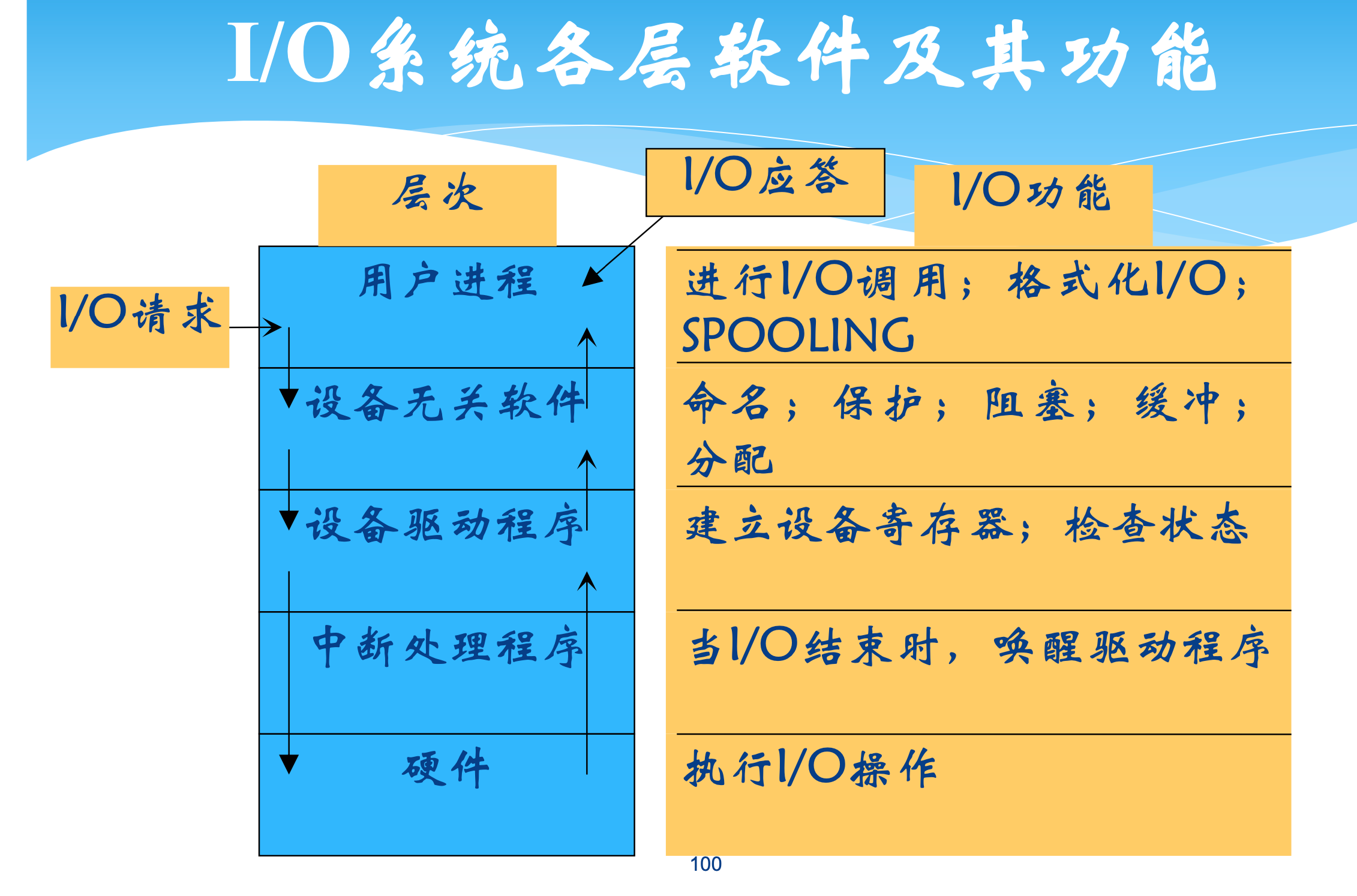
I/O系统各层软件及其功能
Unbuffered I/O & Buffered I/O
- Unbuffered I/O:
- read/write ->System calls
- File descriptor
- Not in ANSI C, but in POSIX.1 and XPG3
- Buffered I/O
- Implemented in standard I/O library (属于库函数,而不是系统调用)
- 处理很多细节, 如缓存分配, 以优化长度执行I/O等.
- Stream -> a pointer to FILE
RAID
略
File
- 进程是虚拟化的CPU, 地址空间是虚拟化的内存, 而文件和目录就是虚拟化的外部存储设备
- 文件:线性字节数组,每个文件都有一个低级名称:
inode number - 目录:目录是特殊的文件,本身也有低级名称
inode number,其内容为(用户可读名字, 低级名称)对的列表。- 目录的每个对,即每个条目
dentry,都指向文件或其他目录 - 目录层次结构从根目录
/开始
- 目录的每个对,即每个条目
Linux文件的细节详见Linux Programming
File System
整体组织
我们实现极简版的VSFS( Very Simple File System ), VVFS与Linux的VFS(虚拟文件系统,提供了统一的文件系统模型,详见Linux Basic)大致相同:
- 磁盘分块(block),文件系统由一系列块组成
- 假定有64块,每块4KB. 数据块为最后56个,inode表占5个,两种位图各占一个,超级块占一个
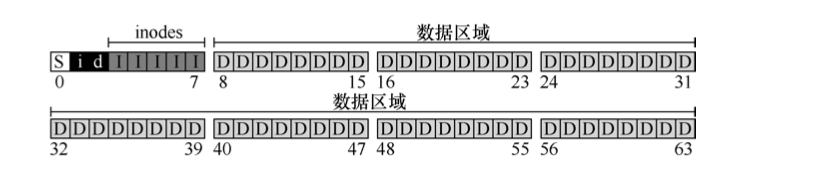
superblock:位于第一块, 记录关于该文件系统的信息, 包括inode和数据块数量,inode表的起始地址等。 和一些标识文件系统类型的magic number- 位图(bitmap):记录inode或数据块是否已分配的数据结构,有
inode bitmap和data bitmap inode表:就是inode数组- 数据块
| 超级块 | inode bit map | data bitmap | inode table | datablock |
|---|---|---|---|---|
| 1 | 1 | 1 | 5 | 56 |
- 挂载文件系统时,OS首先读取
superblock,初始化各种参数,然后将该卷添加到文件系统树中- 也就是说挂载文件系统时,超级块必定被加载到内存里
文件组织: inode
index node, named by Ken Thompson
inode:保存给定文件的元数据的结构由
inumber隐式引用, 给定inumber,可以计算磁盘上相应节点的位置假设:
- inode表大小为20KB(5个4KB块)
- 每个
inode256字节,因此有80个inode; - 超级块0KB开始,
inode map从4KB开始,data map从8KB开始,inode table从12字节开始 - 要读取
inode number=32
过程:
先得到inode表的起始地址:
12KB再加上此
inode在表内的偏移量:32 * 256B = 8192B,12KB + 8192B= 20KB由于磁盘不是字节可寻址的,而是由可寻址扇区组成(512B),因此为了获取
inumber=32的inode块,文件系统将请求物理节点号40(20KB / 512B= 40),获得期望的inode块
1
2
3#通用算法: inumber -> sector number
blk = ( inumber * sizeof(inode_t) )/ blockSize; # 得到该inode所在的块号
sector = ((blk*blockSize)+ inodeStartAddr)/ sectorSize;
多级索引
为了支持大文件,inode中除了直接指针外,还允许间接指针。 间接指针指向一个间接块(磁盘的数据块区域)。 假设一个块是4KB,磁盘地址空间是4Byte, 那就增加了1024个指针。 假设inode有12个直接指针和一个间接指针,则一个inode可以支持\((12+ 1 \times 1024) \times 4 \mathrm{KB}\)
按这个逻辑,还可以分配一个二重间接块,存放指向间接块的指针, inode存放一个二重间接指针, 这个指针就可以表示\(1024 \times 1024 \mathrm{KB}\)
注意到,使用了多级索引的文件系统的文件分配模型是一个不平衡树,这个设计的初衷是: 大部分文件都是小文件, 因此只需要对大文件进行特殊的设计, 小文件让直接指针指向就好了
还有一种基于链表的方法,即inode只需存储一个指向第一个块的指针, 而数据区每个数据块的末尾都会有一个指向该文件下一个数据块的指针。但是这种方式对于某些workload效果不好,比如随机访问。
- windows采用FAT(File Allocation Table), 指向下一块的指针不存在当前数据块中, 而是存在FAT(位于内存)中
目录组织
目录是特殊的文件,它也有inode, 但是目录的内容(即数据块的内容)是目录条目(称为dentry )与该条目对应inode的映射
打开目录,首先是打开目录的文件描述符
目录基本上是一个<dentry, inode number>的列表。 其中条目名称还包括条目的记录长度(名称的总字节数 + 所有的剩余空间)和字符串长度(即条目名称的实际长度)。 每个目录还有两个额外的条目: .和.. 用于表示当前目录和父目录
- 目录就是特殊的文件, 它也有inode, 目录的数据块的内容就是以上说的
<条目名称, inode number>的列表
假设某目录(i number = 5)中有三个文件(foo, bar, foo bar), i number分别为12,13和24,则dir在磁盘上的数据是:
| inum | reclen | strlen | name |
|---|---|---|---|
| 5 | 4 | 2 | . |
| 2 | 4 | 3 | .. |
| 12 | 4 | 4 | foo |
| 13 | 4 | 4 | bar |
| 24 | 8 | 7 | foobar |
删除一个文件会在目录中留下一段空白空间, 一般是将该文件对应条目的inum设为一个保留的inum(例如0)
目录的内容虽然位于数据块,但它一般被认为是元数据, 因此在写入日志时,会被当作元数据(而不是物理数据)处理
空闲空间管理
文件系统必须记录哪些inode和数据块是空闲的,这样在分配新文件/新目录时,就可以使用空闲的inode和数据块, 这就是空闲空间管理
VFSFS中使用位图进行空闲空间管理, 然而也有别的方法, 比如空闲列表和B树等
- 空闲列表:(超级块中的有一个空闲指针,指向第一个空闲块,此后每个空闲块内部都有指向下一个空闲块的指针
文件访问
假设文件系统已经挂载,要读取文件/foo/bar, 要读取该文件(也就是该文件的数据块),需要先找到该文件的inode, 文件系统必须遍历路径名,才能找到inode, 所有遍历都从文件系统的根目录开始。 即文件系统会先读入inode为2的块, 然后找到/foo的inumber和块,最后找到/foo/bar的inumber和块
- 一般而言,根目录的inode number为2
- 这种遍历方式会导致, 访问文件导致的IO与路径长度成正比,路径上的每个目录都会被读取
read()系统调用不会查询位图,因为只有要分配空间时(比如write())才需要查询分配结构
缓存
如前所述,每次文件访问都会读取路径上的所有目录,为此可以用缓存,将数据保留在内存中, 分为读缓存和写缓存
- 写缓存: 显然,写入数据最终必须要写入磁盘,这看上去和缓存没什么关系。然而,写缓存可以将一组写入操作编成一批(batch), 再延迟写入, 一次延迟写入就处理一批写操作
为了避免缓存,可以用fsync()来强制写入磁盘, 甚至可以不使用文件系统,直接使用原始磁盘接口(raw disk interface)来写入数据(数据库就经常这么干, 因为数据库坚持自己控制一切)
Locality and FFS
内存是随机访问的,但目前为止的磁盘都是顺序访问的,OS通过抽象,把磁盘抽象成了内存,让程序以为所有空间都是随机访问的,这就导致了某些workload会导致磁盘性能不佳,因为毕竟底层是顺序访问
解决这个问题,需要文件系统面向磁盘设计。为此,Berkley的一个小组设计了FFS(Fast File System),它将磁盘分为一些组,称为柱面组(或称为块组),将两个有关联的块放到同一分组,这样访问的时候可以提高效率
- 举例来说,FFS将文件的inode所在块和数据块放在一起(因为这二者必定有关联),避免长时间寻道
- “有关联”还可以建立在局部性原理上,例如,FFS将同一目录下的所有文件尽量放在一组,因为按照局部性原理,这些文件被经常一起访问
由于大文件无法全部放入一个分组,因此FFS会将某些块(比如inode块)分配到一个组, 而大块房贷单独的分组。这会导致磁盘碎片化。 当然,允许的块越大,这种碎片也就越少
FFS的贡献:
- 引入了面向磁盘的文件系统
- 引入了软链接
- 引入了
rename()系统调用
Crush-Consistency Problem
崩溃一致性问题 : 更新持久数据结构时发生崩溃,解决方案有fsck和日志
向文件写数据时,要更新至少三个块:更新的inode(比如,要增加新的指针), 更新的数据块和更新的数据位图
这三个块的写入操作,无论哪个出问题,都会导致崩溃后不一致
在元数据日志中,我们会看到, 解决崩溃一致性的核心,就是先写入被指对象,再写入指针对象,这样能保证数据的正确性
示例
示例:对于如下文件系统结构,有一个inode位图,一个数据位图,一个inode表(包含8个inode)和一个数据块表(包含8个数据块)

( 这里inode bmap和data bmap实际指向了下标3和5,应该是图画错了 )
可以看到,已经分配了一个inode(inumber=2),它在inode位图中标记, 单个分配的数据块Da(数据块4)也在数据位图(记为B[v1], 表示第一个版本))中标记, inode表示为I[v1],即该inode的第一个版本,I[v1]的内容有:
1 | owner :lyk |
- 文件大小为1 ( 有一个数据块 ), 第一个直接指针指向块4, 且所有其他直接指针都是null
假如要向文件追加内容,比如要增加一个数据块, 此时要更新至少三个块:更新的inode(比如,要增加新的指针), 更新的数据块和更新的数据位图:
我们希望更新后的inode(用I[v2]表示)内容如下:
1 | owner :lyk |
- 更新后的数据位图(记为
B[v2])要变成: 00001100 - 新增的数据块记为Db
我们希望最终的文件系统如下所示:
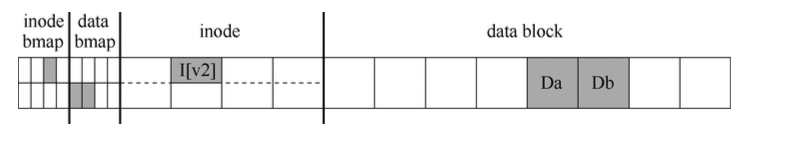
然而,对I[v2], B[v2], Db 这三个块的写入操作,无论哪个出问题,都会导致崩溃后不一致
FSCK
File System Checker
一个UNIX工具,在文件系统挂载之前执行, 可以保证,fsck检查结束后,文件系统时一致的
fsc会检查超级块,空闲块,inode状态,inode链接等信息, 事实上,fsck会扫描整个磁盘(另一方面,出现不一致的可能只是几个数据块), 因此fsck的代价非常大
Journalist
Linux的ext2文件系统没有日志 ,日志是由ext3引入的
带有日志的ext3文件系统如下所示:

- 可以看到,这里对块/柱面进行了分组
Data Journaling
数据日志就是将要更新的物理内容也写进日志里
对于之前的示例,加入数据日志后,文件系统的日志区域如下所示:

这里写了五个块:
- 事务开始TxB: 此更新的相关信息,以及事务标识符(TID)
- 物理日志: 这里占三个块,就是更新的确切物理内容
- 事务结束TxE: 也会包含TID
更新文件系统分为三个步骤:
日志写入: 将食物的内容(包括TxB, 元数据和数据)写入日志,等待这些写入完成
日志提交: 将事务提交块(包括TxE)写入日志,事务被认为已提交(committed)
加检查点: 将更新内容(元数据和数据)写入磁盘
释放: 一段时间后,通过更新日志超级块(不是主文件系统的超级块), 在超级块中标识该事物为空闲
- 这一步和事务的原子性没有关系,只是为了重用日志空间。日志空间如果满了,就无法提交事务了,因此日志被实现为循环数据结构,一旦事务被加检查点,文件系统就应该释放它在日志中占用的空间,允许重用日志空间
- 要达到这个目的有很多方法,比如在日志超级块中标记最新和最旧的事务
![journaling circyling journalist]()
- 这一步和事务的原子性没有关系,只是为了重用日志空间。日志空间如果满了,就无法提交事务了,因此日志被实现为循环数据结构,一旦事务被加检查点,文件系统就应该释放它在日志中占用的空间,允许重用日志空间

注意,如果将TxE在日志写入阶段一并提交(即没有日志提交步骤),那么在日志写入阶段发生崩溃时(即将以上五个块发生崩溃时),会出现问题。 因此, 日志总是要分为日志写入和提交两阶段,来确日志的原子性
崩溃恢复:
- 如果在步骤2之前崩溃,那可以跳过这个更新(事务),因为没有该事物的日志,崩溃后的系统根本不知道这个事务的存在
- 如果在步骤3之前崩溃,系统只需要replay日志中的食物,这称为redo logging
- 如果在加检查点时发生崩溃,处理方式如步骤2
缺点: 数据日志需要将待更新数据写入磁盘两次,一次写入日志空间,一次写入真正的待更新区域,这是巨大的开销,为此,我们一般使用元数据日志
Metadata Journaling
元数据日志与数据日志几乎相同,但是物理数据没有写入日志,而是直接写入文件系统
但是,物理数据不能在事务提交后再写入文件系统,否则即使replay日志,也无法恢复数据(因为此时的日志中没有物理数据),所以,应该首先进行数据写入,这可以保证指针永远不会指向垃圾, 其核心理念是先写入被指对象,再写入指针对象:
- 物理数据写入
- 日志元数据写入: 将开始块TxB和元数据写入日志
- 日志提交
- 加检查点元数据: 将元数据更新的内容写入文件系统
- 释放
元数据日志的缺点是块复用问题, 因为目录的内容被当作元数据而不是物理数据,这意味着(在元数据日志中)目录的内容会放在日志空间。 假设某目录的内容在日志空间中占用块1000, 随后用户删除该目录,并释放块1000, 最后用户创建了新文件,并复用了块1000(此时该块位于物理数据空间), 此时,在日志提交后,加检查点完成之前发生了崩溃,在replay阶段, 会重放日志中所有内容, 那么新文件的内容(也就是块1000)就会被恢复为目录的内容! 这都是因为目录的内容被视作元数据,而不是物理数据,保留在日志空间
Linux ext3点解决方案是加入撤销(revoke)指令,在上例中,删除目录将导致revoke指令被添加到日志,在replay时,被revoke的数据(这里是目录的内容)将不会被重放