awk
awk is a an interpreted programming language that is good at processing text streams
ref: awk tutorial
AWK
workflow
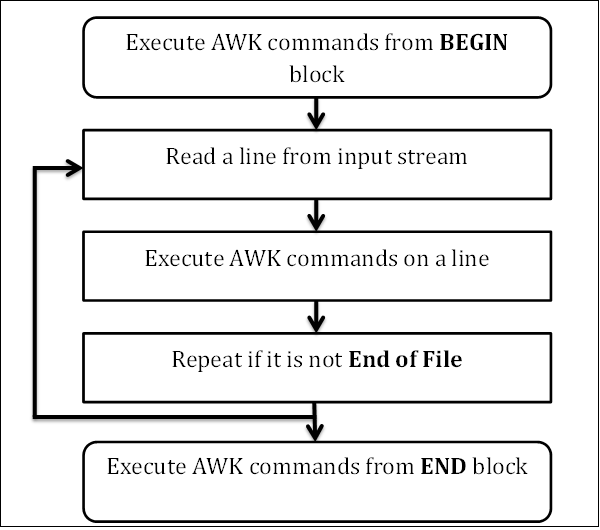
Read
AWK reads a line from the input stream (file, pipe, or stdin) and stores it in memory.
Execute
All AWK commands are applied sequentially on the input. By default AWK execute commands on every line. We can restrict this by providing patterns.
Repeat
This process repeats until the file reaches its end.
Program Structure
Let us now understand the program structure of AWK.
Body Block
The syntax of the body block is as follows −
Syntax
1 | /pattern/ {awk-commands} |
awk programs take the form of an optional pattern plus a block saying what to do if the pattern matches a given line.
The default pattern (which we used above) matches all lines
pattern不仅可以是REGEX,还可以是条件表达式:
1
2输出奇数行
awk -F ':' 'NR % 2 == 1 {print $1}' demo.txtIn the absence of a body block − default action is taken which is print the line.
Inside the block,
$0: entire line’s contents, and$1through$n: thenth field of that line,- fields are separated by the
awkfield separator, (whitespace by default, change with-F)
- fields are separated by the
BEGIN && END block
this block is optional.
Syntax
1 | BEGIN {awk-commands} |
The BEGIN block gets executed at program start-up.
The END block executes at the end of the program
属于 AWK keyword, 必须大写
===================================>
examole:
1
| awk '$1 == 1 && $2 ~ /^c[^ ]*e$/ { print $2 }' | wc -l
- The pattern says that the first field of the line should be equal to 1 (that’s the count from
uniq -c), and that the second field should match the given regular expression. And the block just says to print the username. - We then count the number of lines in the output with
wc -l.
- The pattern says that the first field of the line should be equal to 1 (that’s the count from
command line
- ark command 必须用单引号括起来
1 | awk [options] 'command' target_file |
program File
We can provide AWK commands in a script file
1 | awk [options]-f source_code_file target_file |
standard options
-v: assigns a value to a variable. It allows assignment before the program execution.1
$ awk -v name=Jerry 'BEGIN{printf "Name = %s\n", name}'
--dump-variables[=file]: prints a sorted list of global variables and their final values to file. The default file isawkvars.out1
2$ awk --dump-variables ''
$ cat awkvars.out--help--lint[=fatal]: enables checking of non-portable or dubious constructs. When an argument fatal is provided, it treats warning messages as errors-posix option: turns on strict POSIX compatibility, in which all common and gawk-specific extensions are disabled--profile[=file]: generates a pretty-printed version of the program in file. Default file isawkprof.outexample:
1
2
3awk --profile 'BEGIN{printf"---|Header|--\n"} {print}
END{printf"---|Footer|---\n"}' marks.txt > /dev/null
cat awkprof.outoutput:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# gawk profile, created Sun Oct 26 19:50:48 2014
# BEGIN block(s)
BEGIN {
printf "---|Header|--\n"
}
# Rule(s) {
print $0
}
# END block(s)
END {
printf "---|Footer|---\n"
}--traditional: disables all gawk-specific extensions.
variable
- awk变量不需要定义和声明,可以直接使用,初始值为
0
1 | [jerry]$ awk '/a/{++cnt} END {print "Count = ", cnt}' marks.txt |
built-in variables:
ARGCARGVCONVFMT: It represents the conversion format for numbers. Its default value is%.6gENVIRON: It is an associative array of environment variables.awk 'BEGIN { print ENVIRON["USER"] }'FILENAME: 当前处理的文件名FS: 字段分隔符,默认是空格和制表符, 可以用-F更改awk 'BEGIN {print "FS = " FS}' | cat -vteNF: 表示当前行的字段数,因此$NF就代表最后一个字段。echo -e "One Two\nOne Two Three\nOne Two Three Four" | awk 'NF > 2'1
2$ echo 'this is a test' | awk '{print $NF}'
testNR:表示当前处理的行号OFMT: It represents the output format number and its default value is%.6g.OFS: 输出字段的分隔符,用于打印时分隔字段,默认为空格。awk 'BEGIN {print "OFS = " OFS}' | cat -vteORS: 输出记录的分隔符,用于打印时分隔记录,默认为换行符。
REGEX
与其他语言的regex相同
1 | echo -e "Apple Juice\nApple Pie\nApple Tart\nApple Cake" | awk |
Array
assign :
array_name[index] = value- 不需要定义或声明
index可以是string或number
Creating Array
1
2
3
4
5
6
7
8
9[jerry]$ awk 'BEGIN {
fruits["mango"] = "yellow";
fruits["orange"] = "orange"
print fruits["orange"] "\n" fruits["mango"]
}'
#output
orange
yellowDeleting Array Elements
1
delete array_name[index]
Multi-Dimensional arrays
array_name[index, index] = value
control flow
与其他语言同
if1
2if (condition)
action1
awk 'BEGIN {num = 10; if (num % 2 == 0) printf "%d is even number.\n", num }'
if-else1
2
3
4if (condition)
action-1
else
action-21
2
3
4awk 'BEGIN {
num = 11; if (num % 2 == 0) printf "%d is even number.\n", num;
else printf "%d is odd number.\n", num
}'if -else if1
2
3
4
5
6
7
8
9
10
11awk 'BEGIN {
a = 30;
if (a==10)
print "a = 10";
else if (a == 20)
print "a = 20";
else if (a == 30)
print "a = 30";
}'
loop
for1
awk 'BEGIN { for (i = 1; i <= 5; ++i) print i }'
while1
awk 'BEGIN {i = 1; while (i < 6) { print i; ++i } }'
built-in function
arithmetic function
sin():正弦。cos():余弦。sqrt():平方根。rand():随机数。
string function
length(arg)1
[jerry]$ awk 'length($0) > 18' marks.txt
print item1,item,...各项目间使用逗号分隔开,而输出时以
OFS为分隔printf "format", expr,expr,...1
2
3
4
5
6[jerry]$ awk 'BEGIN {
param = 1024.0
result = sqrt(param)
printf "sqrt(%f) = %f\n", param, result
}'asort(arr [, d [, how] ])This function sorts the contents of arr using GAWK’s normal rules for comparing values, and replaces the indexes of the sorted values arr with sequential integers starting with 1.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26[jerry]$ awk 'BEGIN {
arr[0] = "Three"
arr[1] = "One"
arr[2] = "Two"
print "Array elements before sorting:"
for (i in arr) {
print arr[i]
}
asort(arr)
print "Array elements after sorting:"
for (i in arr) {
print arr[i]
}
}'
#Output
Array elements before sorting:
Three
One
Two
Array elements after sorting:
One
Three
Twoasorti(arr [, d [, how] ])The behavior of this function is the same as that of asort(), except that the array indexes are used for sorting.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17[jerry]$ awk 'BEGIN {
arr["Two"] = 1
arr["One"] = 2
arr["Three"] = 3
asorti(arr)
print "Array indices after sorting:"
for (i in arr) {
print arr[i]
}
}'
#Output
Array indices after sorting:
One
Three
Twogsub(regex, sub, string)global substitution. It replaces every occurrence of regex with the given string (sub). The third parameter is optional. If it is omitted, then $0 is used.
1
2
3
4
5
6
7
8
9
10
11[jerry]$ awk 'BEGIN {
str = "Hello, World"
print "String before replacement = " str
gsub("World", "Jerry", str)
print "String after replacement = " str
}'
#output
String before replacement = Hello, World
String after replacement = Hello, Jerrymatch(str, regex)It returns the index of the first longest match of regex in string str. It returns 0 if no match found.1
2
3
4
5
6
7
8
9
10
11
12
13[jerry]$ awk 'BEGIN {
str = "One Two Three"
subs = "Two"
ret = match(str, subs)
printf "Substring \"%s\" found at %d location.\n", subs, ret
}'
On executing this code, you get the following result −
#Output
Substring "Two" found at 5 locationsplit(str, arr, regex)splits the string str into fields by regular expression regex and the fields are loaded into the array arr. If regex is omitted, then FS is used.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[jerry]$ awk 'BEGIN {
str = "One,Two,Three,Four"
split(str, arr, ",")
print "Array contains following values"
for (i in arr) {
print arr[i]
}
}'
#output
Array contains following values
One
Two
Three
Fourstrtonum(str)This function examines str and return its numeric value. If str begins with a leading 0, it is treated as an octal number. If str begins with a leading 0x or 0X, it is taken as a hexadecimal number. Otherwise, assume it is a decimal number.
1
2
3
4
5
6
7
8
9
10[jerry]$ awk 'BEGIN {
print "Decimal num = " strtonum("123")
print "Octal num = " strtonum("0123")
print "Hexadecimal num = " strtonum("0x123")
}'
#output
Decimal num = 123
Octal num = 83
Hexadecimal num = 291sub(regex, sub, string)This function performs a single substitution. It replaces the first occurrence of the regex pattern with the given string (sub). The third parameter is optional. If it is omitted, $0 is used.
substr(str, start, l)This function returns the substring of string str, starting at index start of length l. If length is omitted, the suffix of str starting at index start is returned.
tolower():字符转为小写
user-defined functions
1 | function function_name(argument1, argument2, ...) { |
example
1 | # Returns minimum number |
redirection
Redirections in AWK are written just like redirection in shell commands, except that they are written inside the AWK program
pretty printing
Horizontal Tab
1
2
3
4awk 'BEGIN { printf "Sr No\tName\tSub\tMarks\n" }'
output
Sr No Name Sub MarksBackspace
\b删除前一个字符1
2
3
4awk 'BEGIN { printf "Field 1\bField 2\bField 3\bField 4\n" }'
Output
Field Field Field Field 4On executing this code, you get the following result −
Format Specifier
同其他语言