Outline:
Intro:
多处理器编程的困难
用状态机理解并发算法
并发控制:互斥、同步
概念: 互斥
并发与状态机
Threading API
Lock
Concurrent Data Structure based on Lock
Conditional Variable
信号量
常见并发问题
基于事件的并发
Ref:
Operating Systems Three Easy pieces
JYY OS
Intro
Concurrent:exsiting, happening, or done at the same time. 程序的不同部分可以按不同顺序执行,且最终得到正确的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <stdio.h> #include <assert.h> #include <pthread.h> void *mythread ( void *arg ) { printf ("%s\n" , arg); return NULL ; } int main ( int argc, char * argv[]) { pthread_t p1,p2; int rc; printf ( "main:begin\n" ); char * ch1 = "A" ; char * ch2 = "B" ; rc = pthread_create( &p1, NULL , mythread, ch1 ); assert(rc==0 ); rc = pthread_create( &p2, NULL , mythread, ch2 ); assert(rc==0 ); rc= pthread_join( p1,NULL ); rc= pthread_join( p2,NULL ); printf ("main:end\n" ); }
该程序打印结果为:
或者
两次运行结果不一样
多任务OS的并发
(假设系统只有一个CPU)
OS可以同时加载多个进程
每个进程都是独立的进程,互不干扰
即使是root权限的进程,也不能直接访问操作系统内核的内存
每隔一段时间,就切换到另一个进程
并发性的来源: 进程会调用OS的API
write(fd,buf,11 TiB)(TiB宏)write的实现是OS的一部分x86-64应用程序执行syscall后就进入OS执行
此时OS允许write的同时,让另一个进程执行
如:另一个进程执行了read(fd,buf,512 MiB)读取同一文件
OS代码并发了 : OS API实现需要考虑并发
虽然进程在地址空间中是独立的,但是OS中的对象是被进程共享的
并发与并行的区别
并发: 多个执行流可以不按照一个特定的顺序执行
并行:允许多个执行流真正地同时执行
单
共享内存
OS内核/多线程程序
并发不并行
多
共享内存
OS内核/多线程程序/GPU Kernel
并发、并行
多
不共享内存
分布式系统(消息通信)
并发、并行
线程
线程: A single process can contain multiple threads, all of which are executing the same program. These threads share the same global memory (data and heap segments), but each thread has its own stack (automatic variables).
多个执行流并发/并行执行,且共享内存
两个执行流共享代码和所有全局变量(数据区、堆区)
线程间指令的执行顺序是不确定(non-deterministic )的
共享:共享代码区(当前进程的代码)、数据区和堆,但不共享寄存器和栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <stdio.h> #include <pthread.h> #include "mythreads.h" static volatile int counter = 0 ;void * mythread ( void *arg ) { printf ( "%s: begin\n" , (char *)arg ); int i; for ( int i = 0 ; i < 1e7 ; i++ ) counter++; printf ("%s: done\n" , (char *)arg); return NULL ; } int main ( int argc, char * argv[]) { pthread_t p1,p2; int rc; printf ( "main:begin ( counter = %d )\n" , counter ); char * ch1 = "A" ; char * ch2 = "B" ; Pthread_create( &p1, NULL , mythread, ch1 ); Pthread_create( &p2, NULL , mythread, ch2 ); Pthread_join( p1,NULL ); Pthread_join( p2,NULL ); printf ("main:done with both ( counter = %d )\n" , counter); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <pthread.h> void Pthread_create (pthread_t *__restrict __newthread, const void * __attr, void *(*__start_routine) (void *), void *__restrict __arg) { pthread_create( __newthread, __attr, __start_routine, __arg ); } void Pthread_join (pthread_t __th, void **__thread_return) { pthread_join( __th, __thread_return ); } void *Malloc (unsigned size) { return malloc (size); }
输出为:
1 2 3 4 5 6 main:begin ( counter = 0 ) A: begin B: begin A: done B: done main:done with both ( counter = 12275324 )
可以看到结果不是200000, 而是12275324
再运行一次:
1 2 3 4 5 6 main:begin ( counter = 0 ) A: begin B: begin B: done A: done main:done with both ( counter = 10467369 )
两次运行的结果都不一样!
多处理器编程的困难
原子性: 即使是i++,也会被分成几个指令
顺序性:代码 的编译器优化
可见性: CPU 可以不按顺序执行指令。没有前后依赖就会被优化(并行执行)
并发术语
临界区( critical section ): 访问共享资源的一段代码
竞态条件( race condition ): 多个执行线程大致同时进入进阶区时,都试图更新共享资源的情况
不确定性( indeterminate ): 程序含有竞态条件,其输出不确定
同步原语( synchronization primitive ):硬件提供指令,在其上构建同步原语,实现原子性
互斥原语( mutual exclusion ): 线程应该使用互斥原语,以保证只有一个线程进入临界区,从而避免出现竞态,并产生确定的程序输出
概念:互斥
互斥(mutual exclusion)
1 2 3 4 5 typedef struct {... }lock_tl void lock (lock_t *lk) ;void unlock (lock_t *lk) ;
我们假设CPU有三种指令:
load: mem -> reg
store: reg -> mem
本地计算: 线程的寄存器做一些计算,结果存入寄存器
共享内存上互斥的困难
并发与状态机
程序 = 有限状态机 = 有向图
图论是理解程序的重要工具
不确定(non-deterministic)的指令可能有多个状态
获取处理器的”时间戳“用于精确定时
机器提供的”真“随机数
syscall
状态机模型:应用
Time - Travel Debugging
Record & Replay
确定的程序不需要任何记录,只需要再执行一次
只需记录non-deterministic指令的效果 (side-effect),就可实现重放
线程间通信ITC
(1)通信线程位于同一个进程中,共享相同的地址空间
(2)通信线程位于不同的进程中,拥有不同的地址空间
相同进程
对于情况(1),线程间的通信可以直接通过访问共享的地址空间 实现信息交换
不同进程
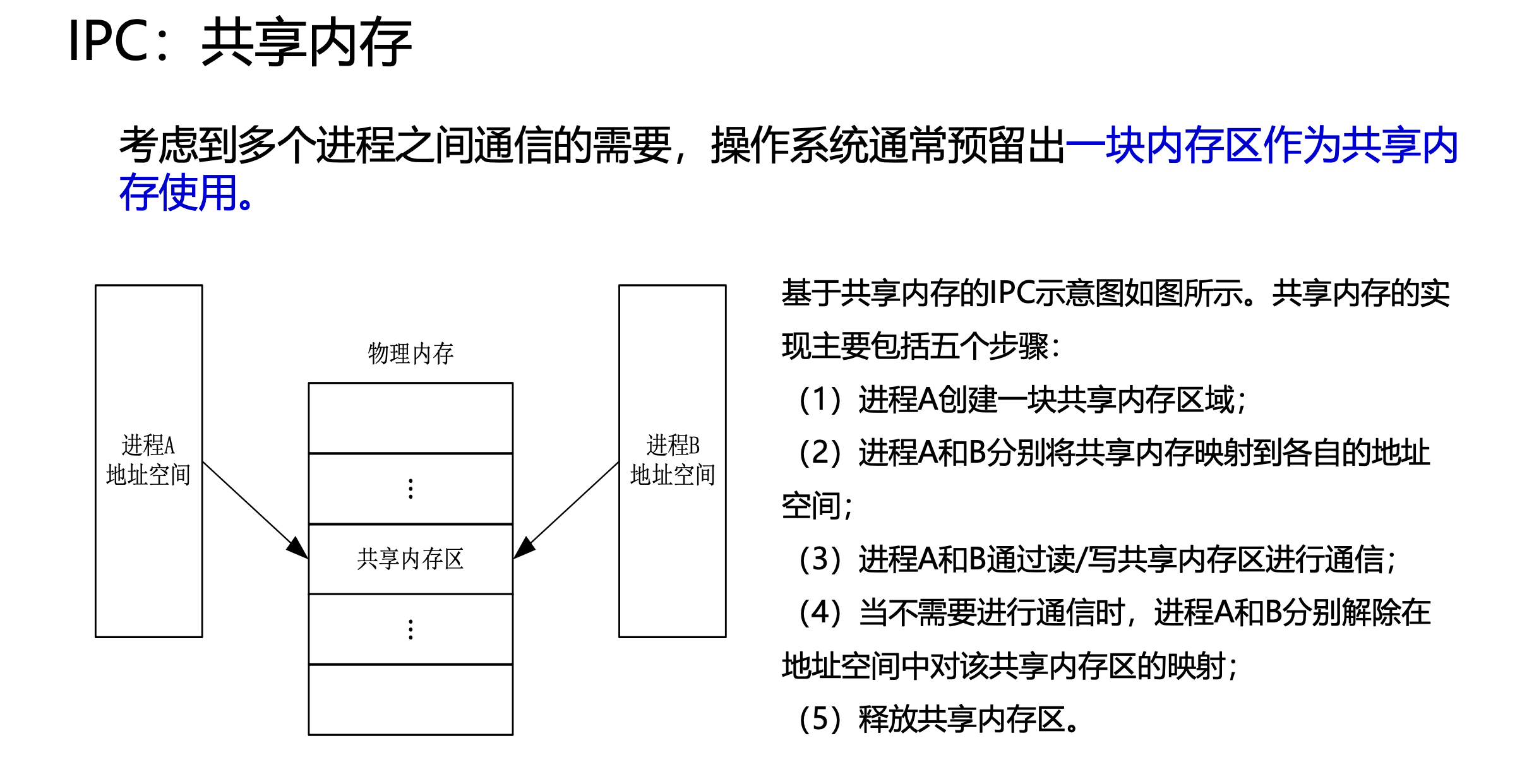
对于情况(2), 采用进程间通信IPC
• IPC机制主要包括:信号(Signal)、管道(Pipe)、信号量、共享内存(Shared Memory)、消息队列(Message Queue)、套接字(Socket)
• 与线程间通信机制不同,进程间通信机制需要打破进程间地址空间的隔离
某些OS发行版(.其实就是欧拉 )增加的IPC机制:共享内存, 消息通信
共享内存是一种在进程间高效地传递大量信息的通信方式。但在共享内存机制下,信息的发送方不关心信息由谁接收,而信息的接收方也不关心信息是由谁发送的,这存在安全隐患。
消息传递允许进程不必通过共享内存区来实现通信,而是通过交换消息的方式来实现通信。消息 传递关注信息的发送者不接收者,通过使用内核拷贝传递的信息,完成进程间的信息传递
image-20220408144852516
Threading API
man -k pthread
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <stdio.h> #include <pthread.h> #include "mythreads.h" #include <stdlib.h> typedef struct myarg_t { int a; int b; }myarg_t ; typedef struct myret_t { int x; int y; }myret_t ; void * mythread ( void *arg ) { myarg_t *m = (myarg_t *)arg; printf ( "args: %d %d\n" , m -> a, m -> b ); myret_t *r = Malloc(sizeof ( myret_t )); r -> x = 1 ; r -> y = 2 ; return (void *) r; } int main ( int argc, char * argv[]) { pthread_t p; int rc; myret_t *m; myarg_t args; args.a = 10 ; args.b = 20 ; Pthread_create( &p, NULL , mythread, &args ); Pthread_join( p, ( void **) &m ); printf ("returned: %d %d\n" , m -> x, m -> y ); }
输出为:
1 2 args: 10 20 returned: 1 2
线程创建
<pthread.h>
1 2 3 4 5 6 7 extern int pthread_create (pthread_t *__restrict __newthread, const pthread_attr_t *__restrict __attr, void *(*__start_routine) (void *), void *__restrict __arg) __THROWNL __nonnull ((1 , 3 )) ;
线程完成
1 2 3 4 5 6 7 8 9 10 11 extern int pthread_join (pthread_t __th, void **__thread_return) ;
锁
1 2 3 4 5 6 7 8 9 10 extern int pthread_mutex_lock (pthread_mutex_t *__mutex) extern int pthread_mutex_unlock (pthread_mutex_t *__mutex) pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;pthread_mutex_init(*lock, NULL ) extern int pthread_mutex_destroy (pthread_mutex_t *__mutex)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 #include <pthread.h> #include <stdlib.h> #include <assert.h> typedef pthread_cond_t cond_t ;typedef pthread_mutex_t mutex_t ;void Pthread_create (pthread_t *__restrict __newthread, const void * __attr, void *(*__start_routine) (void *), void *__restrict __arg) { int rc = pthread_create( __newthread, __attr, __start_routine, __arg ); assert( rc == 0 ); } void Pthread_join (pthread_t __th, void **__thread_return) { int rc = pthread_join( __th, __thread_return ); assert( rc == 0 ); } void *Malloc (unsigned size) { return malloc (size); } void Pthread_mutex_lock ( pthread_mutex_t *mutex ) { int rc = pthread_mutex_lock(mutex); assert( rc == 0 ); } void Pthread_mutex_unlock ( pthread_mutex_t *mutex ) { int rc = pthread_mutex_unlock(mutex); assert( rc == 0 ); } void Pthread_mutex_init ( pthread_mutex_t *__mutex, const void *__mutexattr ) { int rc = pthread_mutex_init(__mutex, NULL ); assert( rc == 0 ); } void Pthread_mutex_destroy ( pthread_mutex_t *__mutex ) { int rc = pthread_mutex_destroy(__mutex); assert( rc == 0 ); } void Pthread_cond_init ( pthread_cond_t *__restrict __cond, const void *__restrict __cond_attr ) { int rc = pthread_cond_init( __cond, __cond_attr); assert( rc == 0 ); } void cond_destroy ( pthread_cond_t *__restrict __cond ) { int rc = pthread_cond_destroy(__cond); assert( rc == 0 ); } void Pthread_cond_wait (pthread_cond_t *__restrict __cond, pthread_mutex_t *__restrict __mutex) { int rc = pthread_cond_wait(__cond, __mutex); assert(rc ==0 ); } void Pthread_cond_signal (pthread_cond_t *__cond) { int rc = pthread_cond_signal(__cond); assert( rc==0 ); }
使用锁:
1 2 3 4 5 6 pthread_mutex_t lock;Pthread_mutex_init( &lock ,NULL ); Pthread_mutex_lock( &lock ); x = x +1 ; Pthread_mutex_unlock( &lock );
条件变量
1 2 3 4 5 6 7 8 9 10 extern int pthread_cond_wait (pthread_cond_t *__restrict __cond, pthread_mutex_t *__restrict __mutex) ; extern int pthread_cond_signal (pthread_cond_t *__cond) ;
1 2 3 4 5 6 7 pthread_cond_t cond = PTHREAD_COND_INITIALIZER;pthread_cond_init( __cond, __cond_attr); extern int pthread_cond_destroy (pthread_cond_t *__cond) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 void Pthread_cond_init ( pthread_cond_t *__restrict __cond, const void *__restrict __cond_attr ) { int rc = pthread_cond_init( __cond, __cond_attr); assert( rc == 0 ); } void cond_destroy ( pthread_cond_t *__restrict __cond ) { int rc = pthread_cond_destroy(__cond); assert( rc == 0 ); }
Lock
锁的状态:
方法:
lock(): 尝试获取锁,如果锁是available,则获取锁,进入临界区unlock(): 使锁available
锁提供了最小程度的调度控制
通常用不同的锁保护不同的数据( 细粒度的方案 )
评价锁
有效性: 提供互斥
公平性fairness: 当锁可用时,是否每一个竞争线程有公平的机会抢到锁
性能performance
控制中断
最早提供的互斥解决方案之一,就是在临界区关闭中断:
1 2 3 4 5 6 7 void lock () { DisableInterrupts(); } void unlock () { EnableInterrupts(); }
假设在单CPU系统上,这段代码在临界区关闭中断,从而原子地执行,结束后又重新打开中断
test-and-set
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 typedef struct lock_t ( int flag; ) lock_t ; void init ( lock_t *mutex ) { mutex -> flag = 0 ; } void lock ( lock_t *mutex ) { while ( mutex -> flag == 1 ) ; mutex -> flag = 1 ; } void unlock ( lock_t *mutex ) { mutex -> flag = 0 ; }
这段代码有两个问题:
正确性:
( 初始时,flag == 0 ) call lock()
while( flag == 1 )
interrupt: switch to Thread2
call lock()
while( flag == 1 )
flag = 1;
interrupt: switch to Thread 1
flag = 1( too ! )
性能问题:
这个锁是自旋 的,一个线程自旋等待另一个线程释放锁,浪费时间
对于单CPU,因为同一时间只有一个线程,且自旋的线程永远不会放弃CPU,本线程自旋时,持有锁的线程根本无法运行,也不可能释放锁
需要抢占式的调度器( preemptive scheduler , 即不断通过时钟中断一个线程,运行其他线程 )
用test-and-set实现锁
1 2 3 4 5 6 int TestAndSet ( int *old_ptr, int new ) { int old = *old_ptr; *old_ptr = new; return old; }
compare-and-exchange
fetch-and-add
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int FetchAndAdd ( int *ptr ) { int old = *ptr; *ptr = old + 1 ; return old; } typedef struct lock_t { int ticket; int turn; } lock_t ; void lock_init ( lock_t *lock ) { lock -> ticket = 0 ; lock -> turn = 0 ; } void lock (lock_t *lock) { int myturn = FetchAndAdd( &lock->ticket ); while ( lock-> turn != myturn ) ; } void unlock ( lock_t *lock ) { FetchAndAdd( &lock-> turn ); }
解释:ticket是一个全局的号码,turn是全局的轮次。 每个用户从ticket得到自己的turn, 每交易一次,ticket++. 只有到达自己的turn的用户才能进入临界区,每当一个用户从临界区出来, turn++
本方法能保证所有线程都能抢到锁,只要一个线程获得了ticket,就能被调度
自旋过多的解决方案
我们已经实现了有效、公平( 借助ticket)的锁,但自旋会导致性能降低
方案一 yield
1 2 3 4 5 void lock () { while ( TestAndSet(&flag, 1 ) == 1 ) yield(); }
假定OS提供原语yield(),可以让线程从running变为ready
假设100个线程竞争1个锁,该方案会yield99次,比自旋99次好,但仍不够完美
方案二 使用队列: 休眠代替自旋
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 1 typedef struct lock_t {2 int flag;3 int guard;4 queue_t *q;5 } lock_t ;6 7 void lock_init (lock_t *m) {8 m->flag = 0 ;9 m->guard = 0 ;10 queue_init(m->q);11 }12 13 void lock (lock_t *m) {14 while (TestAndSet(&m->guard, 1 ) == 1 )15 ; 16 if (m->flag == 0 ) {17 m->flag = 1 ; 18 m->guard = 0 ;19 } else {20 queue_add(m->q, gettid());21 m->guard = 0 ;22 park();23 }24 }25 26 void unlock (lock_t *m) {27 while (TestAndSet(&m->guard, 1 ) == 1 )28 ; 29 if (queue_empty(m->q))30 m->flag = 0 ; 31 else 32 unpark(queue_remove(m->q)); 33 m->guard = 0 ;34 }
看不懂QAQ,为啥unpark的时候不把flag设为0啊,这样所有其他进程都无法获得锁
Concurrent Data Structure Based on Lock
通过锁使得数据thread safe
可扩展性: 理想状态下的多线程的每个线程就和单线程一样快,二者的比值就是并发方法的扩展性
并发计数器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 1 typedef struct counter_t {2 int value;3 pthread_mutex_t lock;4 } counter_t ;5 6 void init (counter_t *c) {7 c->value = 0 ;8 Pthread_mutex_init(&c->lock, NULL );9 }10 11 void increment (counter_t *c) {12 Pthread_mutex_lock(&c->lock);13 c->value++;14 Pthread_mutex_unlock(&c->lock);15 }16 17 void decrement (counter_t *c) {18 Pthread_mutex_lock(&c->lock);19 c->value--;20 Pthread_mutex_unlock(&c->lock);21 }22 23 int get (counter_t *c) {24 Pthread_mutex_lock(&c->lock);25 int rc = c->value;26 Pthread_mutex_unlock(&c->lock);27 return rc;28 }
扩展并发计数器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 1 typedef struct counter_t {2 int global; 3 pthread_mutex_t glock; 4 int local[NUMCPUS]; 5 pthread_mutex_t llock[NUMCPUS]; 6 int threshold; 7 } counter_t ;8 9 10 11 void init (counter_t *c, int threshold) {12 c->threshold = threshold;13 14 c->global = 0 ;15 pthread_mutex_init(&c->glock, NULL );16 17 int i;18 for (i = 0 ; i < NUMCPUS; i++) {19 c->local[i] = 0 ;20 pthread_mutex_init(&c->llock[i], NULL );21 }22 }23 24 25 26 27 void update (counter_t *c, int threadID, int amt) {28 pthread_mutex_lock(&c->llock[threadID]);29 c->local[threadID] += amt; 30 if (c->local[threadID] >= c->threshold) { 31 pthread_mutex_lock(&c->glock);32 c->global += c->local[threadID];33 pthread_mutex_unlock(&c->glock);34 c->local[threadID] = 0 ;35 }36 pthread_mutex_unlock(&c->llock[threadID]);37 }38 39 40 int get (counter_t *c) {41 pthread_mutex_lock(&c->glock);42 int val = c->global;43 pthread_mutex_unlock(&c->glock);44 return val; 45 }
并发链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 1 2 typedef struct node_t {3 int key;4 struct node_t *next ;5 } node_t ;6 7 8 typedef struct list_t {9 node_t *head;10 pthread_mutex_t lock;11 } list_t ;12 13 void List_Init (list_t *L) {14 L->head = NULL ;15 pthread_mutex_init(&L->lock, NULL );16 }17 18 int List_Insert (list_t *L, int key) {19 pthread_mutex_lock(&L->lock);20 node_t *new = malloc (sizeof (node_t ));21 if (new == NULL ) {22 perror("malloc" );23 pthread_mutex_unlock(&L->lock); 24 return -1 ; 25 }26 new->key = key;27 new->next = L->head;28 L->head = new;29 pthread_mutex_unlock(&L->lock);30 return 0 ; 31 }32 33 int List_Lookup (list_t *L, int key) {34 pthread_mutex_lock(&L->lock);35 node_t *curr = L->head;36 while (curr) {37 if (curr->key == key) {38 pthread_mutex_unlock(&L->lock); 39 return 0 ; 40 }41 curr = curr->next;42 }43 pthread_mutex_unlock(&L->lock);44 return -1 ; 45 }
在开头lock,结尾unlock, 注意到malloc失败后也要记得unlock
这种在代码中多次unlock的写法很丑陋! 应该修改
要么出错的地方不要放在临界区
要么出错时break到主循环,在主循环内统一unlock
这是粗粒度的写法,可以更细粒度地优化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 18 int List_Insert (list_t *L, int key) {19 20 node_t *new = malloc (sizeof (node_t ));21 if (new == NULL ) {22 perror("malloc" );23 pthread_mutex_unlock(&L->lock); 24 return -1 ; 25 }26 new->key = key;27 28 pthread_mutex_lock(&L->lock);29 new->next = L->head;30 L->head = new;31 pthread_mutex_unlock(&L->lock);32 return 0 ; 33 }33 int List_Lookup (list_t *L, int key) { int rv = -1 ; 34 pthread_mutex_lock(&L->lock);35 node_t *curr = L->head;36 while (curr) {37 if (curr->key == key) {38 rv=0 ;39 break ; 40 }41 curr = curr->next;42 }43 pthread_mutex_unlock(&L->lock);44 return rv; 45 }
扩展链表
过手锁hand-overohand locking: 每个节点都有一个锁,替代之前整个链表一个锁,遍历链表时,首先抢占下一个节点的锁,然后释放当前节点的锁
注意控制流的变化导致函数返回和退出,这种情况下要记得释放锁
并发队列
粗粒度的锁很简单,接下来使用细粒度的锁
对队列头和尾各设置一个锁
因为出队只访问head锁, 入队只访问tail锁, 两把锁使得出队和入对可以并发执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 1 typedef struct node_t {2 int value;3 struct node_t *next ;4 } node_t ;5 6 typedef struct queue_t {7 node_t *head;8 node_t *tail;9 pthread_mutex_t headLock;10 pthread_mutex_t tailLock;11 } queue_t ;12 13 void Queue_Init (queue_t *q) {14 node_t *tmp = malloc (sizeof (node_t ));15 tmp->next = NULL ;16 q->head = q->tail = tmp;17 pthread_mutex_init(&q->headLock, NULL );18 pthread_mutex_init(&q->tailLock, NULL );19 }20 21 void Queue_Enqueue (queue_t *q, int value) {22 node_t *tmp = malloc (sizeof (node_t ));23 assert(tmp != NULL );24 tmp->value = value;25 tmp->next = NULL ;26 27 pthread_mutex_lock(&q->tailLock);28 q->tail->next = tmp;29 q->tail = tmp;30 pthread_mutex_unlock(&q->tailLock);31 }32 33 int Queue_Dequeue (queue_t *q, int *value) {34 pthread_mutex_lock(&q->headLock);35 node_t *tmp = q->head;36 node_t *newHead = tmp->next;37 if (newHead == NULL ) {38 pthread_mutex_unlock(&q->headLock);39 return -1 ; 40 }41 *value = newHead->value;42 q->head = newHead;43 pthread_mutex_unlock(&q->headLock);44 free (tmp);45 return 0 ;46 }
并发散列表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1 #define BUCKETS (101) 2 3 typedef struct hash_t {4 list_t lists[BUCKETS];5 } hash_t ;6 7 void Hash_Init (hash_t *H) {8 int i;9 for (i = 0 ; i < BUCKETS; i++) {10 List_Init(&H->lists[i]);11 }12 }13 14 int Hash_Insert (hash_t *H, int key) {15 int bucket = key % BUCKETS;16 return List_Insert(&H->lists[bucket], key);17 }18 19 int Hash_Lookup (hash_t *H, int key) {20 int bucket = key % BUCKETS;21 return List_Lookup(&H->lists[bucket], key);22 }
Conclusion
Knuth定律: 避免不成熟的优化
先最简单的方案,也就是加大锁( big kernel lock, BKL. in linux kernel )开始, 如果有性能问题再改进
控制流变化时记得获取和释放锁
增加并发并不一定能提高性能
Conditional Variable
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <stdio.h> #include <pthread.h> #include "mythreads.h" #include <stdlib.h> int done = 0 ;pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;pthread_cond_t c = PTHREAD_COND_INITIALIZER; void thr_exit () { Pthread_mutex_lock(&m); done = 1 ; Pthread_cond_signal(&c); Pthread_mutex_unlock(&m); } void thr_join () { Pthread_mutex_lock(&m); while (done==0 ) Pthread_cond_wait(&c,&m); Pthread_mutex_unlock(&m); } void * child ( void *arg ) { printf ( "child\n" ); thr_exit(); return NULL ; } int main ( int argc, char * argv[]) { pthread_t p; printf ("parent: begin\n" ); Pthread_create(&p, NULL ,child, NULL ); thr_join(); printf ("parent: end\n" ); return 0 ; }
情况一: parent创建出子进程后,自己继续运行(假设单核),然后马上调用thr_join() 等待子进程,此时它会先获取锁,检查子进程是否完成(还没有),然后调用wait(),让自己休眠。 子线程最终得以运行,打印出“child”, 并调用thr_exit()唤醒父进程, 而exit()原子地设置done,向父进程signal, 最后父进程会运行,从wait()返回并持有锁, 释放锁, 打印出“parent: end”
情况二:子进程创建后立刻运行, 设置done = 1, 调用signal()唤醒其他线程(这里没有其他线程),然后结束。 副进程运行后,调用thr_join()时,发现done已经为1了,就直接返回
1 2 3 parent: begin child parent: end
状态变量done是必要 的
假如没有:
1 2 3 4 5 6 7 8 9 10 11 12 13 void thr_exit () { Pthread_mutex_lock(&m); Pthread_cond_signal(&c); Pthread_mutex_unlock(&m); } void thr_join () { Pthread_mutex_lock(&m); Pthread_cond_wait(&c,&m); Pthread_mutex_unlock(&m); }
假如子线程立刻运行,且调用thr_exit,此时子进程signal(),条件变量上没有睡眠的线程。 父线程运行时,就会调用wait()并卡在这里,没有线程会signal()它
发信号和等待时加锁也是必要的
假如没有:
1 2 3 4 5 6 7 8 9 10 11 12 void thr_exit () { done = 1 ; Pthread_cond_signal(&c); } void thr_join () { while (done==0 ) Pthread_cond_wait(&c,&m); }
如果父进程调用thr_join(),检查done = 0,试图睡眠,然而在调用wait()前被中断(因为没有锁,此时其它进程就可以操纵临界区), 子进程修改变量为1,发出signal(),此时没有睡眠进程。 父进程再次运行时,就会卡在wait(),没有线程可以唤醒它
生产者/消费者(有界缓冲区)问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 cond_t cond;mutex_t mutex;int count = 0 ;void *producer (void *arg) { int i; int loops = (int ) arg; for ( i=0 ; i < loops; i++ ) { Pthread_mutex_lock(&mutex); if (count == 1 ) Pthread_cond_wait(&cond,&mutex); put(i); Pthread_cond_signal(&cond); Pthread_mutex_unlock(&mutex); } } void *consumer ( void *arg ) { int i = 0 ; int loops = (int ) arg; for (int i = 0 ; i < loops; i++ ) { pthread_mutex_unlock(&mutex); while ( count == 0 ) pthread_cond_wait(&cond,&mutex); int tmp = get(); Pthread_cond_signal(&cond); Pthread_mutex_unlock(&mutex); ptrintf("%d\n" ,tmp); } }
假设使用if: 假设有两个消费者\(T_{c1}\) 和,\(T_{c2}\) 生产者\(T_{p}\) ,
若\(T_{c1}\) 先运行,卡在wait, 接着\(T_p\) 运行,在缓冲区放一个数字,然后signal唤醒\(T_{c1}\) , 生产者继续循环,直到发现缓冲区满后睡眠
此时如果\(T_{c2}\) 抢先执行,消费了缓冲区里的值,然后\(T_{c1}\) 从wait处恢复运行,调用get,此时发生error!
原因在于,生产者signal唤醒了\(T_{c1}\) , 但是没有保证\(T_{c1}\) 立即执行 (或者说,没有保证\(T_{c1}\) 执行之前,缓冲区没有再发生变化)
解决方案是: 始终使用while ,这样当\(T_{c1}\) 醒来时,会再次检查count==0,发现为缓冲区0则继续wait。这样就避免了error
使用两个条件变量
上述代码依然有问题: 假设\(T_{c1}\) 和\(T_{c2}\) 先运行,都卡在wait, \(T_{p}\) 开始运行,往缓冲区放入一个值,发出signal, 继续循环,直到发现缓冲区满后睡眠
\(T_{c1}\) 醒来,消费了这个值,然后在该条件上signal,注意,此时理应唤醒\(T_{p}\) , 但事实上有可能唤醒\(T_{c2}\) 假如唤醒\(T_{c2}\) ,因为缓冲区为空, 它会卡在wait,此时三个线程都处于睡眠
原因在于, signal没有指向性
解决方案:使用两个条件变量, 生产者睡在empty, 消费者睡在fill
由此也看出,线程唤醒需要满足什么条件,它就应该睡在哪个条件变量上 ,这是条件变量的命名方式
比如消费者需要缓冲区fill才能醒来,因此该条件变量就命名为fill
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 cond_t empty,fill;mutex_t mutex;int count = 0 ;void *producer (void *arg) { int i; int loops = (int ) arg; for ( i=0 ; i < loops; i++ ) { Pthread_mutex_lock(&mutex); if (count == 1 ) Pthread_cond_wait(&empty,&mutex); put(i); Pthread_cond_signal(&fill); Pthread_mutex_unlock(&mutex); } } void *consumer ( void *arg ) { int i = 0 ; int loops = (int ) arg; for (int i = 0 ; i < loops; i++ ) { pthread_mutex_unlock(&mutex); while ( count == 0 ) pthread_cond_wait(&fill,&mutex); int tmp = get(); Pthread_cond_signal(&empty); Pthread_mutex_unlock(&mutex); ptrintf("%d\n" ,tmp); } }
最终版本
这是最终版本,生产者只有缓冲区满了的时候才会睡眠
因此信号量命名为empty有点名不符实( fill也是如此,事实上缓冲区有一个值就可以唤醒消费者了 )
对get()和put()的调用保证上了锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 int buffer[MAX];int fill_ptr = 0 ;int use_ptr = 0 ;int count = 0 ;void put (int value) { buffer[fill_ptr] = value; fill_ptr = (fill_ptr+1 )%MAX; count++; } int get () { int tmp = buffer[use_ptr]; use_ptr = (use_ptr+1 )%MAX; count--; return tmp; } cond_t empty,fill;mutex_t mutex;int count = 0 ;void *producer (void *arg) { int i; int loops = (int ) arg; for ( i=0 ; i < loops; i++ ) { Pthread_mutex_lock(&mutex); if (count == MAX) Pthread_cond_wait(&empty,&mutex); put(i); Pthread_cond_signal(&fill); Pthread_mutex_unlock(&mutex); } } void *consumer ( void *arg ) { int i = 0 ; int loops = (int ) arg; for (int i = 0 ; i < loops; i++ ) { pthread_mutex_unlock(&mutex); while ( count == 0 ) pthread_cond_wait(&fill,&mutex); int tmp = get(); Pthread_cond_signal(&empty); Pthread_mutex_unlock(&mutex); ptrintf("%d\n" ,tmp); } }
覆盖条件
signal只会唤醒一个线程考虑一个内存分配程序。 当没有空闲内存时, \(T_{c1}\) 和\(T_{c2}\) 各自allocate1000和10字节。 它们都因此卡在wait
此时\(T_{p}\) free了50字节,它发出signal,此时有可能唤醒的是\(T_{c1}\) , 后者因为内存不够,依然继续睡眠
上述代码因此无法正常工作
解决方案是采用广播的signal, 即pthread_cond_broadcast() 代替pthread_cond_signal,唤醒所有等待线程,这个条件变量称为广播条件covering condition
会影响性能
该方案虽然很笨,但有时很有用
当然,30_8.c的代码也可以采用此解决方案。 但我当时有更好的办法(用两个条件变量)
信号量
1 2 3 4 5 6 7 8 9 10 11 12 int sem_wait (sem_t *s) { } int sem_post (sem_t *s) { }
二值信号量(锁)
1 2 3 4 5 6 sem_t m;sem_init(&m, 0 , 1 ); sem_wait(&m); sem_post(&m);
假设有两个线程,\(T_{1}\) 调用sem_wait(),将信号量值减为0, 因为0不是负数,因此\(T_{c1}\) 从wait返回并继续,它可以自由进入临界区, 若没有其他线程尝试获取锁,当\(T_{1}\) 调用sem_post()时,会将信号重置为1
如果\(T_{1}\) 持有锁时,\(T_{2}\) 尝试获取锁(即调用sem_wait()),此时它会将信号量减为-1。然后卡在这里。 \(T_{1}\) 再次运行,执行sem_post(), 将信号量值增加到0,唤醒等待的线程(\(T_{2}\) ),然后\(T_{2}\) 就能获取锁
当\(T_{2}\) 执行结束时,执行sem_post(), 将信号量值增加到1
信号量用作条件变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 sem_t s;int count = 0 ;void *child (void *arg) { printf ("child\n" ); sem_post(&s); return NULL ; } int main (int argc, char *argv[]) { sem_init( &s, 0 , 0 ); printf ("parent: begin\n" ); pthread_t c; Pthread_create(c, NULL , child, NULL ); sem_wait(&s); printf ("parent: end\n" ); return 0 ; }
输出为:
1 2 3 parent: begin child parent: end
考虑两种情况:
子进程没有先运行,父进程先调用sem_wait(),将信号量减为-1,父进程卡在wait, 然后子进程运行,调用sem_post(),信号量增加为0,唤醒父线程
子线程在父线程调用sem_post()之前就运行结束,结果正常
生产者/消费者(有界缓冲区)问题
考虑用信号量实现生产者/消费者问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 int buffer[MAX];int fill_ptr = 0 ;int use_ptr = 0 ;int count = 0 ;void put (int value) { buffer[fill_ptr] = value; fill_ptr = (fill_ptr+1 )%MAX; count++; } int get () { int tmp = buffer[use_ptr]; use_ptr = (use_ptr+1 )%MAX; count--; return tmp; } sem_t empty,fill;int count = 0 ;void *producer (void *arg) { int i; int loops = (int ) arg; for ( i=0 ; i < loops; i++ ) { sem_wait(&empty); put(i); sem_post(&fill); } } void *consumer ( void *arg ) { int i = 0 ; int loops = (int ) arg; for (int i = 0 ; i < loops; i++ ) { sem_wait(&fill); int tmp = get(); sem_post(&empty); ptrintf("%d\n" ,tmp); } }
这段代码的问题在于: 对假设MAX大于1,此时可以有两个生产者(\(T_1\) , \(T_2\) )同时调用put(),如果\(T_1\) 先放入数据,然后在更新计时器时中断,\(T_2\) 运行,它会在该位置再放入一个值,发生error
这是因为在MAX>1时,信号量的使用不能保证put()的原子性
解决方案:上锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 int buffer[MAX];int fill_ptr = 0 ;int use_ptr = 0 ;int count = 0 ;void put (int value) { buffer[fill_ptr] = value; fill_ptr = (fill_ptr+1 )%MAX; count++; } int get () { int tmp = buffer[use_ptr]; use_ptr = (use_ptr+1 )%MAX; count--; return tmp; } sem_t empty,fill,mutex;int count = 0 ;void *producer (void *arg) { int i; int loops = (int ) arg; for ( i=0 ; i < loops; i++ ) { sem_wait(&mutex); sem_wait(&empty); put(i); sem_post(&mutex); sem_post(&fill); } } void *consumer ( void *arg ) { int i = 0 ; int loops = (int ) arg; for (int i = 0 ; i < loops; i++ ) { sem_wait(&mutex); sem_wait(&fill); int tmp = get(); sem_post(&empty); sem_post(&mutex); ptrintf("%d\n" ,tmp); } } int main () { sem_init(&empty, 0 , MAX); sem_init(&fill, 0 , 0 ); sem_init(&mutex, 0 , 1 ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 int buffer[MAX];int fill_ptr = 0 ;int use_ptr = 0 ;int count = 0 ;void put (int value) { buffer[fill_ptr] = value; fill_ptr = (fill_ptr+1 )%MAX; count++; } int get () { int tmp = buffer[use_ptr]; use_ptr = (use_ptr+1 )%MAX; count--; return tmp; } sem_t empty,fill,mutex;int count = 0 ;void *producer (void *arg) { int i; int loops = (int ) arg; for ( i=0 ; i < loops; i++ ) { sem_wait(&empty); sem_wait(&mutex); put(i); sem_post(&mutex); sem_post(&fill) } } void *consumer ( void *arg ) { int i = 0 ; int loops = (int ) arg; for (int i = 0 ; i < loops; i++ ) { sem_wait(&fill); sem_wait(&mutex); int tmp = get(); sem_post(&mutex); sem_post(&empty); ptrintf("%d\n" ,tmp); } } int main () { sem_init(&empty, 0 , MAX); sem_init(&fill, 0 , 0 ); sem_init(&mutex, 0 , 1 ); }
读者 --- 写者锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 typedef struct _rwlock_t { sem_t lock; sem_t writelock; int readers; }rwlock_t ; void rwlock_init ( rwlock_t *rw ) { rw -> readers = 0 ; sem_init( &rw -> lock, 0 , 1 ); sem_init( &rw -> writelock, 0 , 1 ); } void rwlock_acquire_readlock (rwlock_t *rw) { sem_wait(&rw->lock); rw -> readers++; if (rw->readers == 1 ) sem_post( &rw ->writelock ); sem_post(&rw -> lock); } void rwlock_release_readlock (rwlock_t *rw) { sem_wait(&rw->lock); rw -> readers--; if ( rw -> readers == 0 ) sem_post( rw -> writelock ); sem_post(&rw->lock); } void rwlock_acquire_writelock (rwlock_t *rw) { sem_wait(&rw-> writelock); } void rwlock_release_writelock (rwlock_t *rw ) { sem_post(&rw -> writelock); }
想要获取写锁的进程,需要等待所有的读者都结束
缺点:读者很容易饿死写者
哲学家就餐问题
最简单的解决方案:破除依赖, 就是修改某个哲学家的取餐叉顺序
如何实现信号量
用锁和条件变量实现信号量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <stdio.h> #include <pthread.h> #include "mythreads.h" #include <stdlib.h> #include <semaphore.h> typedef struct _Zem_t { int value; pthread_cond_t cond; pthread_mutex_t lock; }Zem_t; void Zem_init (Zem_t *s, int value) { s -> value = value; Pthread_cond_init(&s->cond,NULL ); Pthread_mutex_init(&s->lock,NULL ); } void Zem_wait (Zem_t *s) { Pthread_mutex_lock(&s->lock); while ( s->value <=0 ) { Pthread_cond_wait( &s->cond, &s->lock ); } s ->value--; Pthread_mutex_unlock(&s->lock); } void Zem_post (Zem_t *s) { Pthread_mutex_lock(&s->lock); s -> value++; Pthread_cond_signal( &s -> cond ); Pthread_mutex_unlock(&s->lock); }
注意到wait是先检查是否为非正数,再递减,这使得信号量值永远不会小于0
用信号量来实现锁和条件变量相当困难
常见并发问题
非死锁缺陷
违反原子性缺陷:给共享变量的访问加锁
违反顺序缺陷:使用条件变量,强制顺序:
1 2 3 4 5 6 7 Pthread_mutex_lock(&mutex); while ( inited == = ) Pthread_Cond_wait( &cond, &mutex ); Pthread_mutex_unlock(&mutex);
死锁缺陷
系统形成死锁的四个必要条件
互斥条件(mutual exclusion):系统中存在临界资源,进程应互斥地使用这些资源
占有和等待条件(hold and wait):进程请求资源得不到满足而等待时,不释放已占有的资源
不剥夺条件(no preemption):已被占用的资源只能由属主释放,不允许被其它进程剥夺
循环等待条件(circular wait):存在循环等待链,其中,每个进程都在链中等待下一个进程所持有的资源,造成这组进程永远等待
循环等待
持有并等待
任何线程抢锁之前要先抢一个全局锁,这样保证了抢锁的原子性(抢锁时不会有其他进程切入)
如:假如线程1需要lock1和lock2, 而线程二需要lock2和lock1。线程1获得lock1后不会被打断,能继续获得lock2,执行完毕,释放这两个锁,线程二继续执行。
1 2 3 4 5 lock(prevection); lock(L1); lock(L2); ... unlock(prevention);
非抢占
1 2 3 4 5 6 7 8 top: lock(L1); if (trylock(L2)==-1 ) { unlock(L1); goto (top); }
同样是实现了原子地抢占锁
会导致活锁( livelock)
两个线程可能一直重复这一序列,又同时都抢锁失败
假如线程1持有lock1,等待lock2( 因此该线程一直try - fail), 而线程二持有lock2,等待lock1,线程1在试图获得lock2时被中断,线程2获得lock2,试图获得lock1,此时发生活锁
互斥
通过调度避免死锁
线程对锁的需求:
只要T1和T2不同时运行就不会发生死锁
T3只用到一把锁,因此可以和其它线程并发执行,不会死锁
可以强制T2在T1之后运行
这种保守的方案很明显会降低性能
检查和恢复
允许死锁偶尔发生,检查到死锁时再采取行动(重启电脑)
太摆烂了。。。
基于事件的并发(Advanced)
事件循环:
1 2 3 4 5 6 7 8 while (1 ){ events = getEvents(); for ( e in events ) { processEvent(e); } }
因为事件是原子的,一次只处理一个事件不需要考虑线程切换。 而且如上所见,我们可以对事件调度进行显式控制
这意味着事件是阻塞的,有巨大的性能开销,需要引入异步的事件处理,再加上多CPU时,并行的事件处理复杂度相当于多线程。 因此给予事件的并发并不比基于线程的简单。
这部分内容很庞大,我不想在C编程上倾注太多时间,因此放在JAVA等语言的并发中讲。