Automated Testing
- Outline:
- 源码测试
- 移动应用
- AI测试
Thanks to 191250025 and other classmates
- This document is used to the Final Review of this course
源码测试
回归测试
基本概念
- 版本迭代后,重新测试用例
- 部分代码修改会影响接口,导致测试用例失效。
- 新需求需要新用例
- 可有效保证代码修改的正确性并避免代码修改对被测程序其他模块产生的副作用。
优化方法
- 测试用例优先级(Test Case Prioritization,TCP)
- 测试用例集约减(Test Suite Reduction,TSR)
- 不考,没记
- 测试用例选择(Test Case Selection,TCS)
差分测试
- 通过将同一测试用例运行到一系列相似功能的应用中观察执行差异来检测bug。(对拍)
蜕变测试
- 依据被测软件的领域知识和软件的实现方法建立的蜕变关系来生成新的测试用例,通过验证蜕变关系是否被保持来决定测试是否通过。( \(sin x=sin(\pi-x)\) )
- 蜕变关系(Metamorphic Relation, MR) 是指多次执行目标程序时,输入与输出之间期望遵循的关系
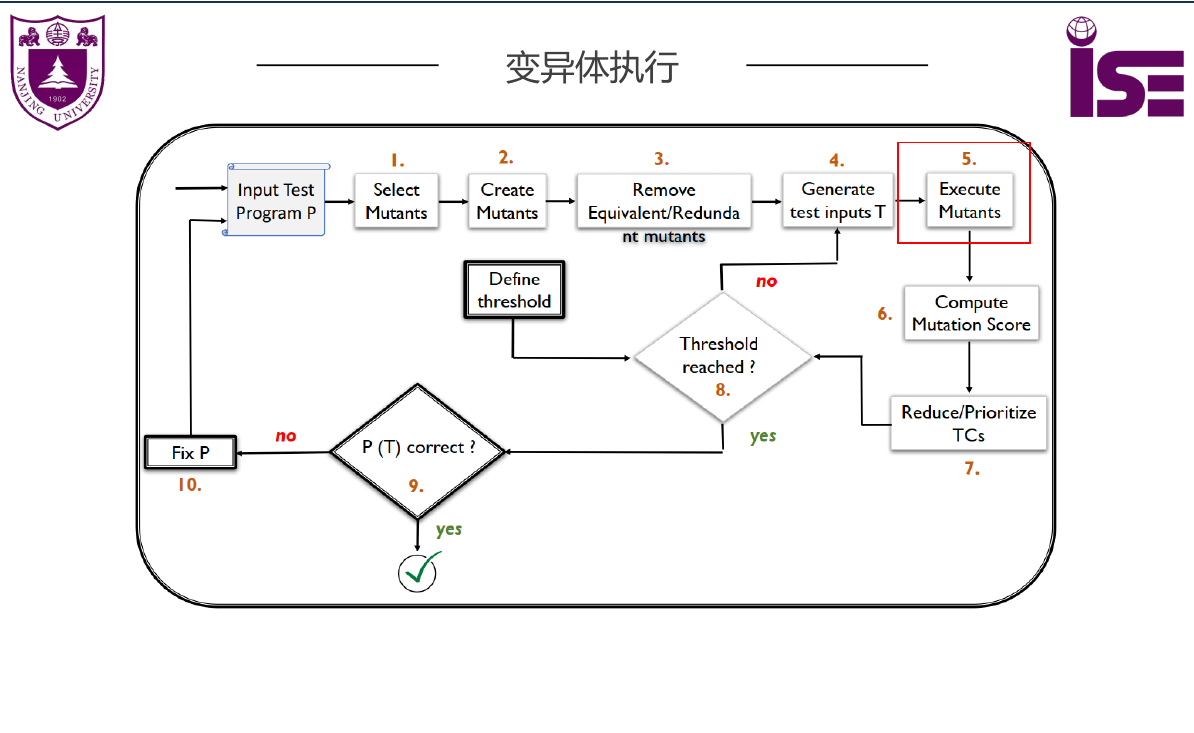
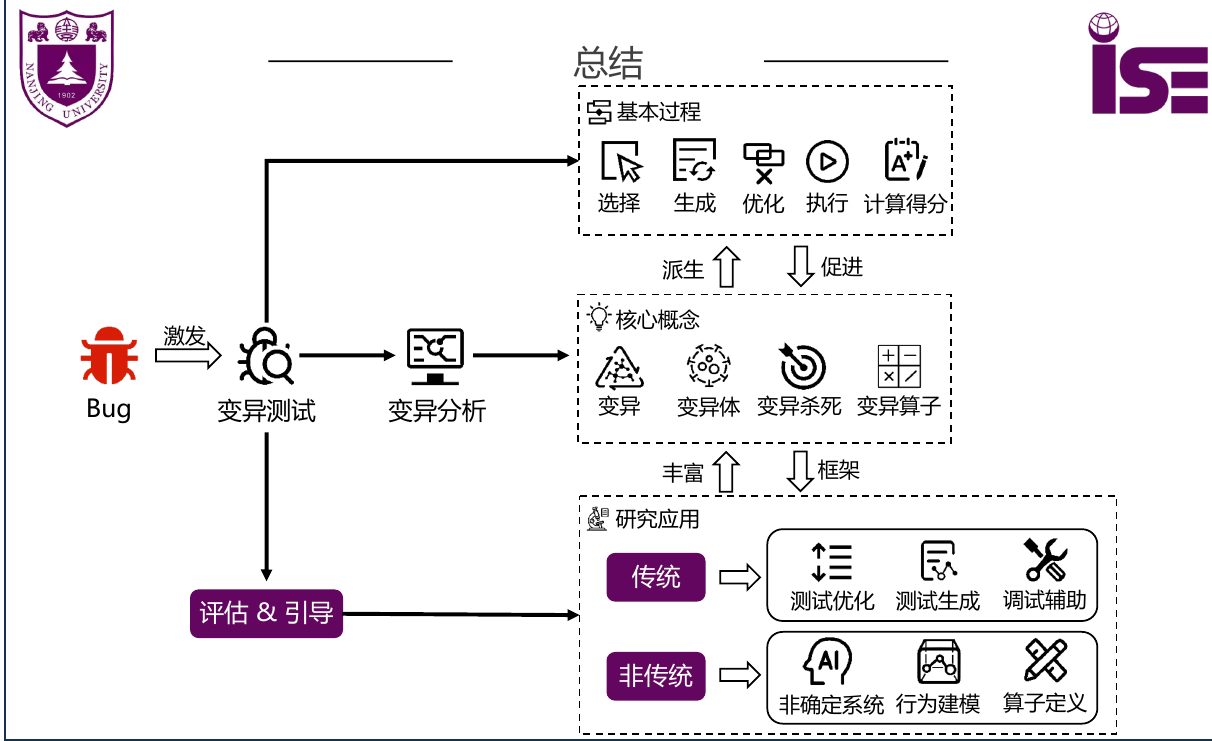
变异测试
- 通过定义好的变异操作来对源码进行修改,以此来帮助测试者定位测试数据的弱点,避免执行测试的弱点
测试用例优先级
- 简介:
- 依照某种策略赋予每个测试用例的不同优先级,以提高测试套件的故障检测率。
- 测试优先级排序技术采用特定的(启发式)算法计划测试用例,使得优先级较高的用例能够先于优先级低的用例执行。
- 类型:
- 通用测试排序:为有利于后续版本的测试用例赋予更高的优先级。
- 特定于版本的测试排序:根据不同软件版本的特性为测试用例分配优先级。
主要算法的流程及复杂度
基于贪心的TCP
- 全局贪心策略
- 每轮优先挑选覆盖最多代码单元的测试用例。
- 多个用例相同随机选择。
- 增量贪心策略
- 每轮优先挑选覆盖最多,且未被已选择用例覆盖代码单元的测试用例。
- 所有代码单元均已被覆盖则重置排序过程
- 多个用例相同随机选择
基于相似性的TCP
基本定义:每轮优先与已选择测试用例集差异性最大的测试用例。让测试用例均匀地分布在输入域中。
- (类似PRIM算法)
排序步骤:
测试用例之间的距离计算:假设\(U(t_1)\) 和 \(U(t_2)\)为测试用例\(t_1\)和\(t_2\)所覆盖的代码单元集合,那么这两个用例之间的距离计算如下: \[ Jaccard(t_1,t_2)=1 - \frac { | U(t_1) \cap U(t_2)|}{| U(t_1) \cup U(t2) |} \]
用例与测试用例集之间的距离计算:分别使用最小距离、平均距离和最大距离度量方式计算待选择用例\(t_c\)与已选择用例集S的距离: $$ D(tc,S)= {
\[\begin{aligned} \max \left\{ \min\limits_{0\leq i \leq |S|} \left\{ Jaccard(t_c, t_i)\right\} \right\} \\ \max \left\{ \underset{0 \leq i \leq|S|}{\operatorname{avg}} \left\{ Jaccard(t_c, t_i)\right\} \right\} \\ \max \left\{ \max\limits_{0\leq i \leq |S|} \left\{ Jaccard(t_c, t_i)\right\} \right\} \\ \end{aligned}\]
. $$
- \(t_c\)是待选用例。这里是计算tc跟已选测试用例集每个ti的距离。假设已选k个用例,则有k个距离,min就是取k个距离中最小的距离作为tc到已选集(包含k个测试用例)的距离。
基于搜索的TCP
基本定义:探索用例排序组合的状态空间,以此找到检测错误更快的用例序列。
排序步骤:
种群构造:生成N个测试用例序列,之后随机生成切割点,互相交换两个用例序列切割点后部分的片段,仅交换相同测试用例的部分;同时以一定概率选择测试用例,并随机生成两个测试用例位置,进行互换,产生新的测试用例序列。
评估值计算:以语句覆盖为例,给定程序包含m个语句\(M = \{s_1,s_2,...,s_m\}\)和n个测试用例\(T=\{t_1,t_2,...,t_n\}\),\(T'\)为某一次搜索中\(T\)的一个排序序列,\(TS_i\)为该测试用例序列\(T'\)中第一个覆盖语句\(s_i\)的测试用例下标,那么其适应度计算为: \[ APSC = 1 - \frac {TF_1+TF_2+ \dots + TF_m}{n * m} + \frac {1}{2n} \]
基于机器学习的TCP策略
基本定义:基于测试分布特征,预测表现最佳的排序技术。
排序步骤:
测试分布特征提取:给定被测程序,提取每个测试用例覆盖单元数;执行时间与单元时间内覆盖单元数。
模型生成:由于三种特征取值范围不同,使用min-max正则化,最后使用XGBoost学习特征进行预测。
APFD计算
APFD:(Average Percentage of Faults Detected )平均故障检测百分比
给定程序包含m个故障\(F=\{f_1,f_2,...,f_m\}\)和n个测试用例\(T=\{t_1,t_2,...t_n\}\),\(T'\)为\(T\)的一个排序序列,\(TF_i\)为该测试用例序列\(T'\)中第一个检测到故障\(f_i\) 的测试用例下标,则该排序序列\(T'\)的APFD值计算公式为 \[ APFD = 1 - \frac {TF_1+TF_2+ \dots + TF_m}{n * m} + \frac {1}{2n} \]
测试用例选择
- 简介:
- 回归测试用例选择可以通过重新运行原始测试套件的一个子集,验证某些变更是否对当前软件版本的功能造成了影响。
- 优点:
- 降低回归测试的开销
- 最大化缺陷探测能力
- 流程:
- 给定修改前的程序\(P\),对应的测试用例集\(T\),和修改后的程序\(P'\)
- 寻找\(T\)的子集\(T'\)对\(P'\)进行测试,并且\(T'\)中的任意测试用例均是可以检测代码修改的测试用例。
主要方法
最小化测试用例选择
- 从\(T\)中找出最小的子集\(T_{min}\),\(T_{min}\)能够覆盖\(P\)中所有本次修改的、或者受本次修改影响的部分。
- 每一条新增的或者被修改的语句都能够被至少一个来自\(T\)的测试用例执行。
安全测试用例选择
从\(T\)中选出能够暴露\(P'\)中的一个或多个缺陷的所有测试用例,构成安全回归测试集\(T_S\)
\(T_S\)中的每个测试都能够满足以下条件之一
执行至少一条在\(P'\)中被删除的语句
执行至少一条在\(P'\)中新增的语句
基于数据流和覆盖的测试用例选择
- 变更后的代码\(P'\)中使数据交互变化的语句构成语句集合\(S_I\)。从原本的测试用例集\(T\)中选取出所有覆盖到\(S_I\)中某条语句的测试用例,组成测试集\(T_D\)
- \(T_D\)中的每个测试都能够满足以下条件之一
- 执行至少一个在\(P'\)中被删除的Define-Use对
- 执行至少一个在\(P'\)中新增的Define-Use对
特制/随机测试用例选择
- 规定测试用例的选取数量为m,测试人员随机地从原本的测试用例集\(T\)中选出m个测试用例,组成随机回归测试集\(T_R\)
- 面向剖面测试用例选择:与AOP有关,从\(T\)中选出与某个剖面a有关的测试用例k,组成回归测试集\(T_a\)
基于程序分析的测试用例选择
- 简介:
通过程序分析技术计算出测试代码(方法、用例或套件)与生产代码之间的依赖关系,并在后者发生变更时,利用这些依赖关系将所有受到变更影响的测试代码(Change-Impacted Tests)自动选取出来,组成回归测试集
一般被认为是一种安全测试用例选择技术
分类:静态,动态
粒度:
- 基本块级、方法级(细)
- 类级、项目级(粗)
阶段:
A Phase –分析阶段:分析代码变更、计算测试依赖 E Phase –执行阶段:运行选中测试 C Phase –收集阶段:收集测试信息
静态
- 在没有实际执行程序的情况下对计算机软件程序进行自动化分析的技术(手动分析一般被称为程序理解或代码审查)。
- 大多数情况下,分析的材料为源语言代码,少部分静态分析会针对目标语言代码进行
- 例如:分析Java的字节码
动态
- 通过在真实或虚拟处理器上执行程序来完成对程序行为的分析。
- 为了使动态程序分析有效,必须使用足够的测试输入来执行目标程序,以尽可能覆盖程序所有的输出。进行动态分析时一般需要注意最小化插桩对目标程序的影响
类的防火墙算法
假设在继承层级(Inheritance Hierarchy)中,类A是类B的子类。当有且仅有B发生变动时,为了保证 测试充分,除B之外,A也应该重新进行单元测试。
假设在聚合层级(Aggregation Hierarchy)中,类A是类B的一个聚合类。当有且仅有B发生变动时,为 了保证测试充分,除B之外,A也应该重新进行单元测试。
假设在关联层级(Association Hierarchy)中,类A与类B的关系满足下列条件之一:
类A访问了类B的数据成员;
类A需要向B传递信息
(简言之: A依赖B)
当B发生变动时,为了保证测试充分,除B之外,A也应该重新进行测试。同时,类A还应该与类B进行重新集成。
动态 vs 静态
| 特征 | 动态 | 静态 |
|---|---|---|
| 总体 | 好 | |
| 依赖信息 | 多 | |
| 开销 | 小 | |
| 过拟合 | 有 | |
| 插桩 | 需要 | 不需要 |
| 运行测试阶段 | 好 |
测试用例优先级 V.S. 测试用例选择
- 优先级技术是对测试用例集进行排序,以最快的速度找到缺陷,提高测试用例集的故障检测率。
- 选择技术是取测试用例集的子集,能覆盖修改过的代码,降低回归测试的开销并最大化缺陷探测能力
移动应用
基于图像理解的移动应用自动化测试
各个任务的难点
- 测试输入生成
- 任务难点:
- 运行环境多样化:网络多样化、平台多样化、设备多样化
- 环境碎片化
- 开发平台快速演化
- 需要考虑系统级事件
- 任务难点:
能够论述各个任务的解决方法
( 只针对测试输入生成 )
- 基于随机:Monkey
- 基于模型:Stout
- 基于机器学习:Q-testing
核心思想
- 测试输入生成即针对给定应用进行测试探索
- 移动应用结构可以抽象为图结构
方法步骤
(Stout)
模型构建
UI页面层次结构 – 事件识别
随机有限状态机(动态分析)
系统事件分析
事件执行频率 – 初始概率
模型变异、测试生成与执行
- 随机变异事件转换概率
- 基于概率生成测试
- 随机注入系统事件
- 测试执行
- 输出度量(覆盖率)
- Gibbs取样(是否继续执行)
- 缺陷诊断
基于群智协同的众包测试
- 众包测试树

- 众包的难点
- 大量重复报告
- 大量不完善报告
- 测试力度分布不均
- 不能充分利用用户合作,验证问题
- 整理归类报告困难,相似报告分散,浪费时间精力
- 审核人员不能专注于质量控制,交付的报告质量较低
基本机制
- 协同推荐:众测系统上发布测试任务(任务发布者)
- 质量保证:众包工人参与测试任务,协作方式完成BUG报告(众包工人)
- 聚合交付:识别并剔除恶意众包工人,审核报告并交付缺陷列表(管理者)
解决方法
协同推荐
- 信息共享,用户提交报告时进行实时相似报告推荐,避免重复报告提交
- 任务分配:用户在提交报告后对其进行审核报告推荐和测试页面推荐。
- 协作方式:用户对于相似报告和审核报告的结果,可以点赞点踩,验证报告有效性。
质量保证
- 众包工人:
- 竞争式提交(独立测试提交报告,贡献归个人所有)、
- 协作式提交(借鉴他人报告,修改他人报告后生成子报告)、
- 审核(对他人报告点赞点踩)
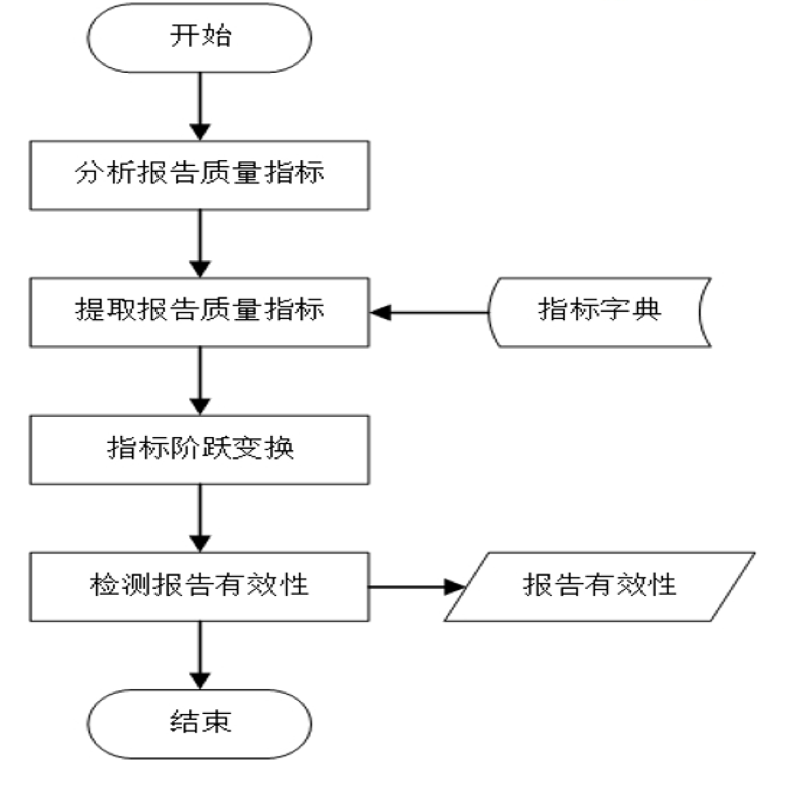
- 质量控制系统:
- bug报告有效性模块
- bug报告自动评估模块
- 反馈与监控模块
- bug报告审核模块
聚合交付
- 过程:
- 聚合阶段: 相似报告聚合
- 融合阶段 :融合相似报告,提高可读性
- 围绕报告融合构建审核业务流程:使审核人员聚焦质量控制
- 目标: 构建一套基于报告融合的测试报告处理流程
AI测试
AI测试概述
与传统测试的区别
- 决策逻辑:
- 传统软件:程序代码控制决策逻辑
- 智能软件:深度学习模型的结构、训练后得到的权重节点
- 系统程序特征:
- 传统软件:控制流和数据流构建的业务处理
- 智能软件:数据驱动构建的参数化数值计算
- 智能软件系统的缺陷往往不是显式的代码或参数错误
测试的难点
数据量不够、低质量数据、数据分布不均、不充分测试
数据驱动的测试
- 需求分析
- 数据采集
- 数据标注
- 模型结构设计
- 模型训练
- 模型测试
- 模型部署
模糊测试
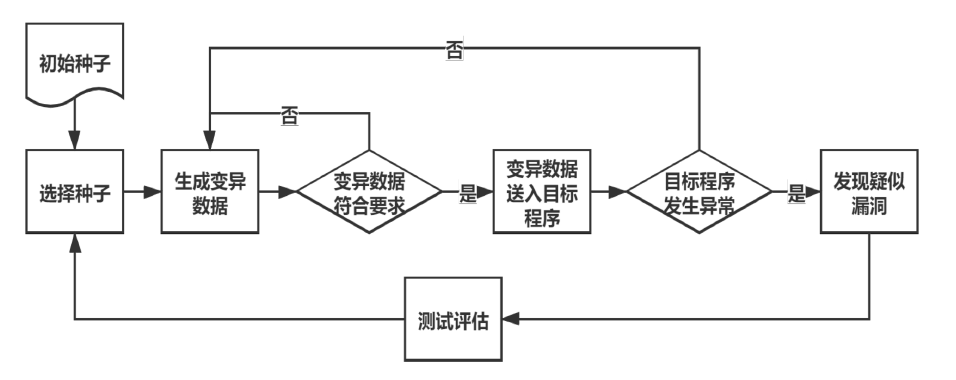
基本流程
- 通过异常的输入自动化发现待测程序缺陷
- 预期输入:变异数据
- 预期输出:断言失败、无效输入、异常崩溃、错误输出
图像扩增
通过轻微变换现有数据或创建新的合成图像来得到新数据的技术。应用领域有图像扩增、文本扩增、雷达扩增......
- 目的:增加数据量、丰富数据多样性、提高模型的泛化能力。
扩增的原则
- 不能引入无关的数据
- 扩增总是基于先验知识的,对于不同的任务和场景,数据扩增的策略也会不同。
- 扩增后的标签保持不变
常用扩增方法
原样本扩增
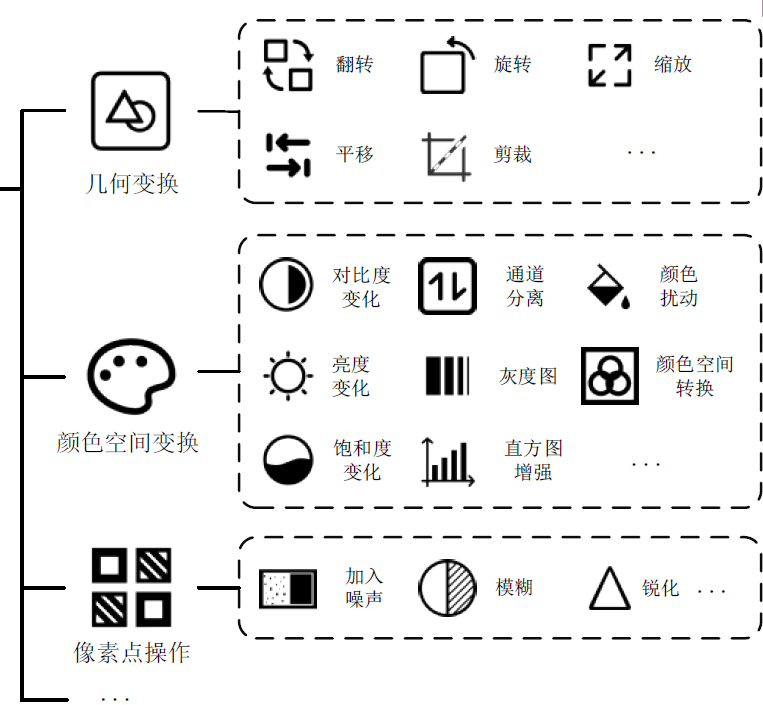
单样本扩增
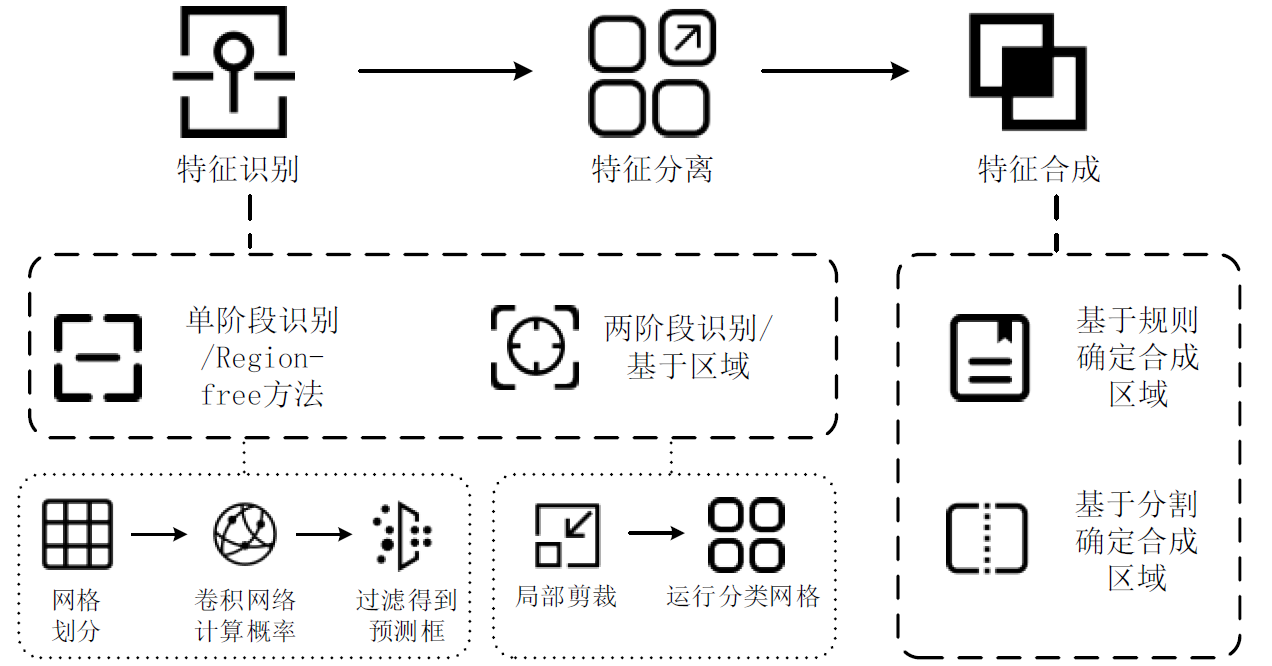
- 两阶段:找到可能包含物体的区域 -> 对该区域进行分类
- 单阶段:图片缩放划分等分网络,并且卷积后过滤获得最后预测框。
- 特征合成:基于规则、基于分割确定合成区域
多样本扩增
样本级合成:标签a的特征 + 标签b的特征 = 标签a
![image-20201101132624376]()
![]()
![image-20201101132643639]()
特征级合成:将不同特征在同一张图上面重新排列组合
标签降级:变成不同的特征



医疗图像扩增的特点
- 图像中不同形式的细微结构可能代表某种病变
- 不能保证扩增的质量
- 不同疾病要使用不同的扩增方法
医疗图像扩增的难点
- 患者隐私保护,医学影像匮乏
- 共享临床数据困难
- 影像质量参差不齐
- 需要专家手动贴标签