Application Layer
Outline:
- DNS
- P2P
- 文件传送协议
- TELNET
- 万维网
- DHCP
域名系统DNS
port:53
概述
- 把互联网上的主机名字转换为IP地址
- DNS被设计为一个联机分布式数据库系统, 并采用CS模式。 DNS使大部分名字都在本地进行解析(resolve), 仅少量解析需要在互联网上通信。
- 由于是分布式系统,单个计算机的故障不会妨碍整个DNS系统的运行
- 解析是通过域名服务器程序, 而运行它的机器称为域名服务器
- 解析过程
- 当某一个应用进程需要把主机名解析为IP地址时, 它就调用解析程序( resolver), 并成为DNS的一个客户, 把带解析的域名放在DNS请求报文中, 以
UDP用户数据报的方式发给本地域名服务器( 使用UDP是为了减小开销 ) - 本地域名服务器在查找域名(递归, 迭代, 详见下文) 后, 把对应的IP地址放在回答报文中返回
- 应用进程获得目的主机的IP地址后即可进行通讯
- 当某一个应用进程需要把主机名解析为IP地址时, 它就调用解析程序( resolver), 并成为DNS的一个客户, 把带解析的域名放在DNS请求报文中, 以
其他服务
- 主机别名
- 原名称为“规范主机名”
- 邮件服务器别名
- 负载分配:将一个IP地址集合(即服务器集合)映射到一个规范主机名。 每次client向集合中的一个元素请求时,DNS以整个集合进行响应(每次返回集合中的一个元素,而整个集合的次序在不断变化,这样就实现了负载分配)
互联网的域名结构
任何连接在互联网的主机和路由器, 都有一个唯一的层次结构的名字, 即域名(Domain name ), 域是一个可被管理的划分. 域可以被划分为子域, 再划分为子域的子域....
每个域名都由一个 label 序列组成,各label间用 .隔开
如: 三级域名 . 二级域名 . 顶级域名
不区分大小写
只是个逻辑概念
域名服务器
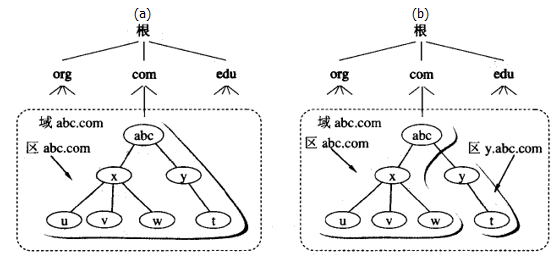
一个服务器管辖的范围叫做区(zone). 每个区内的所有节点是连通的. 每个区设置相应的权限域名服务器( authoritative name server ), 用来保存该区中所有主机的域名到IP地址的映射
DNS查询报文用UDP
DNS服务器的管辖范围以区为单位, 区小于等于域, 是域的子集
- 比如域名abc.com可以只设一个区abc.com, 这样,区和域就是一回事(如左图); 但域名abc.com也可以划分两个区:abc.com 和 y.abc.com 这两个区都隶属于域 abc.com ,都各自设置了相应的权限域名服务器(如又图)
![]()
DNS服务器层次
- DNS服务器按层次安排, 分四种
- 根域名服务器( root name servevr )
- 最高层次
- 直到所有的
顶级域名服务器的域名和IP地址 本地域名服务器自己若无法解析,则首先求助于根域名服务器- 任播(anycast)技术: 找到离DNS客户最近的一个
根域名服务器
- 顶级域名服务器( top level domain name server TLD服务器 )
- 权限域名服务器
- 负责一个区的域名服务器。当它不能给出最后的查询回答时,就会告诉发出查询请求的DNS客户,下一步应该找哪一个权限域名服务器
- 本地域名服务器( local name server ) ( 默认域名服务器 )
- 当一个主机发出DNS查询请求时,这个查询请求报文就发给LNS
- 也称为“默认域名服务器”
- 当所要查询的主机也属于同一个本地ISP时, 该本地域名服务器就能立即将所查询的主机名转换为IP地址
- 根域名服务器( root name servevr )
- 域名解析过程:
- 主机向本地域名服务器递归查询( recursive query )
- 本地域名服务器以DNS客户的身份,向其它根域名服务器发送查询报文
- 因此递归查询的返回结果要么是要查的IP地址,要么是报错,表示没查到
- 本地域名服务器向根域名服务器迭代查询(iterative query)
- 让LNS去查,根域名服务器通常把自己知道的顶级域名服务器的IP地址告诉LNS,让LNS再向顶级域名服务器查询。
- 顶级域名服务器收到LNS的查询请求后,要么给出所查询的IP地址,要么告诉LNS下一步应当向哪个权限域名服务器进行查询
- 主机向本地域名服务器递归查询( recursive query )
DNS缓存
- DNS广泛使用高速缓存
- 为维护缓存中的内容正确,还应给每项内容设一个计时器
- 主机也需要(DNS的)高速缓存,主机启动时从LNS中下载名字和地址的全部数据库,并且维护(DNS)存放自己最近使用的域名的高速缓存
DNS记录和报文
资源记录Resource Record: 所有DNS服务器共同实现了DNS分布式数据库,其条目就是资源记录
(Name, Value,Type,TTL)Name和Value值取决于Type:
Type = A: Name = 主机名, Value = 主机名对应的IP地址Type = NS:Name = 域名,Value = 知道如何获得该域中IP地址的权威DNS服务器的主机名- 与
Type=A记录结合,将权限DNS的主机名进一步映射到权限域名服务器的IP地址,方便迭代查询
- 与
Type=CNAME: Value = 别名为Name的主机的规范主机名Type = MX: Value = 别名为Name的邮件服务器的规范主机名- 使用
MX记录使得邮件服务器可以和其他服务器使用相同的别名,DNS client得到别名后,只需请求一条MX记录,就能得到规范主机名
- 使用
权威域名服务器包含其区内主机的
Type A记录,非权威域名服务器包含的是包含主机名的域的Type = NS记录和Type=A记录,后者提供了NS记录对应的权限域名服务器的IP地址- 例子:假如
edu TLD服务器不是主机gaia.cs.umass.edu的权限域名服务器,则该服务器将包含:- 一条包括 主机
cs.umass.edu的域记录,如(umass.edu, dns.umass.edu, NS) - 一条A记录,与NS记录配套:
(dns.umass.edu, 128.119.40.111,A) - 这样就实现了迭代查询
- 一条包括 主机
- 例子:假如
Tool:
nslookupDNS报文: 略
向DNS数据库中插入记录: 要到注册登记机构
register,它负责验证域名的唯一性,将该域名输入DNS DataBase. 步骤为:假设要开设网站,注册域名
LYK-love.cn,你需要提交权威DNS服务器的域名和地址, 假设:权威DNS服务器名为dns.LYK-love.cn, 其IP地址为212.212.212.1对每个权威DNS。该
register确保将一个NS和A记录输入TLD cn服务器:1
2( LYK-love.cn, dns.LYK-love.cn, NS )
( dns.LYK-love.cn, 212.212.212.1,A )还可以输入
MX记录,与网站使用相同的别名1
( LYK-love.cn, mail.LYK-love.cn, MX ) //别名使用LYK-love.cn
P2P应用
- CS体系依赖于服务器,P2P减少了对中心化的依赖
P2P文件分发
- 考虑一个应用,它从单一server向大量client(称为对等方
peer)分发一个文件- CS:server负担大
- P2P: 每个对等方能重新分发它所拥有的该文件的任何部分
- 最流行的P2P文件共享协议:
BitTorrent
P2P体系的扩展性
定义:
- \(u_s\): server接入链路的上载速率
- \(u_i\):第\(i\)对等方接入链路的上载速率
- \(d_i\): 第\(i\)对等方接入链路的下载速率
- \(F\): 被分发的文件大小(bit)
- \(N\): 要获得该文件副本的对等方的数量
- \(D\): 分发时间, 所有 \(N\) 个对等方得到该文件的副本所需的时间
- 假设网络具有足够的带宽
CS模式的分发时间(下界): \[ D_{cs} \geq \max\{\frac{NF}{u_s}, \frac{F}{d_{\min}} \} \]
- server必须向 \(N\)个对等方的每个传输该文件的一个副本。因此server必须传输\(NF\) bit, 因为其上载速率是
u_s, 分发时间必定至少为\(\frac{NF}{u_s}\) - 令\(d_{min}\)表示具有最小下载速率的对等方的下载速率,后者获得该文件的 所有
Fbit的时间最少为$ $
- server必须向 \(N\)个对等方的每个传输该文件的一个副本。因此server必须传输\(NF\) bit, 因为其上载速率是
P2P模式的分发时间(下界): \[ D_{P2P} \geq \max\{ \frac{F}{u_s}, \frac{F}{d_{\min}}, \frac{NF}{u_s + \sum\limits_{i=1}^{N}{u_i} } \} \]
- 这里只是最小分发时间的简单表示式
- server必须向至少发送该文件的每个bit一次, \(\frac{F}{u_s}\)
- $ $与CS模式相同
- 系统整体上载能力 \(u_{total} = u_s + u_1 + u_2 + \dots + u_N\), 系统必须向这\(N\)个对等方的每个上载\(F\)比特, 因此总共上载\(NF\) bit, 这不能以快于\(u_{total}\)的速率完成,因此,分发时间也至少是\(\frac{NF}{u_s + \sum\limits_{i=1}^{N}{u_i} }\)
比较两种模式的最小分发时间关于 \(N\)的函数,发现P2P的最小分发时间更小
![]()

BitTorrent
- 洪流
torrent: 参与一个特定文件分发的所有对等方的集合 - 块
chunk:在一个洪流中的对等方彼此下载等长度的文件块- 256KB
- 任何对等方可能在任何时候加入或离开洪流
- 追踪器
tracker: 每个洪流一个,用于追踪洪流中的对等方- 每当对等方加入一个洪流,就向其追踪器
register自己,并周期性通知追踪器自己仍在该洪流中
- 每当对等方加入一个洪流,就向其追踪器
- workflow:
- Alice 加入洪流,追踪器随机从对等方的集合中选一个子集(e.g. 50 个 ),并将它们的IP地址发给Alice
- Alice持有这张列表,试图与表上所有对等方建立TCP连接
- 所有与Alice成功建立连接的对等方称为“邻近对等方”( e.g. \(L\)个 )
- 由于用户可随时加入、离开洪流,因此邻近对等方集合是动态的
- 在任何给定的时间,每个对等方将具有来自该文件的的块子集,Alice周期性地询问每个邻近对等方它们所具有的块列表,得到\(L\)个块列表,然后对她还没有的块发出请求
- 请求哪些块?
- 最稀缺优先(
rarest first): (在Alice没有的块中)请求在邻居中副本数量最少的块
- 最稀缺优先(
- 向哪些向她请求的块中发送?
- “一报还一报”(
tit for tat): Alice 根据当前能够以最高速率向她提供数据的邻居,给出其优先权- “一报还一报”被证明可以被回避
- “一报还一报”(
- 请求哪些块?
分布式散列表
- 分布式散列表(
Distributed Hash Table, DHT): 一种分布式数据库,每个对等方仅保持总体数据库的一个子集- 其条目是
(key - value) pair
- 其条目是
- 为每个对等方分配 \(n\) 位的标识符和
key- 值域: \([0,2^{n}-1]\)
- 对于不是整数的
key,用一个散列函数映射到该区间, 以后我们提起key,指的是它的散列值 - 最邻近后继: 将最邻近对等方定义为
key的最邻近后继,key就放在其最邻近后继上
环形DHT
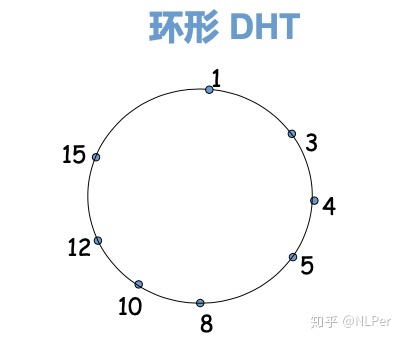
- 假设\(n=4\), 区间为\([0,15]\), 因为对等方
12是键11最邻近的后继, 因此将(11, Johny)存储在对等方12上 - 查询
key时,如何确定最邻近对等方? 需要特殊的对等方拓扑结构:- 所有对等方相连: 这样每个对等方,每个查询仅需一个报文,但这样的系统难以维护
- 环形DHT: 如图,平均发送\(\frac N 2\) 个报文
- “捷径对等方”:在环形基础上增加边
- 普遍采用,每个请求的报文数量能被优化到 \(O(logN)\)
对等方扰动
- P2P系统中,对等方可以自由加入、退出,上述的拓扑结构会被破坏
- 措施: 每个对等方联系其\(n\)个后继(和捷径对等方),这样一个节点消失或增加时,该链表能自己调整
文件传送协议
FTP概述
- FTP( File Transfer Protocal ): 文件传送协议
- 文件共享协议的两大类:
- 复制整个文件,
- 特点是: 若要存取一个文件, 就要先获得一个本地的文件副本。 若要修改文件, 只能对文件的副本进行修改, 然后再将修改后的文件副本传回到原节点
- 两种:
- FTP: 基于TCP
- TFTP: 基于UDP的简单文件传送协议
- 联机访问
- 允许多个程序同时对一个系统进行存取
- 由操作系统提供对远地共享文件进行访问的服务( 不需要调用特殊的进程 ), 就如同对本地文件的访问一样
- 用户可以用远地文件作为输入和输出来运行任何应用程序, 而操作系统中的文件系统则提供对共享文件的透明存取, 其优点是: 将原来用于处理本地文件的应用程序用来处理远地文件时, 不需要对应用程序做明显的改动
- 类似云计算机
- 例子:
- 网络文件系统NFS( Network File System )
- 复制整个文件,
FTP的基本工作原理
CS模式, 一个FTP服务器进程可以同时为多个客户进程提供服务
一个FTP服务器进程由两部分组成:
- 主进程:负责接收新的请求
- 若干个从属进程:负责处理单个请求
主进程的工作步骤:
- 打开熟知端口(21),使客户进程能连接上
- 等待客户进程发出连接请求
- 启动从属进程处理client process发来的请求。 从属进程对 client process 的请求处理完毕后即终止,但从属进程在运行期间还可能创建一些其他的子进程
- 回到等待状态,继续接受其他客户进程发来的请求。主进程与从属进程的处理是并发进行的
- 并发: 在一个芯片上时分复用
FTP工作步骤:
服务器有控制进程。整个会话期间,客户和服务器一直保持控制连接
当客户进程向服务器进程发出建立连接请求时,要寻找连接服务器进程的熟知端口
21,同时告诉服务器进程自己的另一个端口号码,用于建立“数据连接”。客户发送的传送请求,通过控制连接发送给服务器的控制进程
控制进程在接收到文件传输请求后就创建“数据传送进程”和“数据连接”。数据传送进程实际完成文件的传送(通过数据连接),在传送完成后关闭“数据连接”。
服务器进程用自己传输数据的熟知端口
20与客户进程所提供的端口号建立数据传送连接由于FTP将控制连接与数据连接分离,因此FTP的控制信息是带外( out of band )传送的.
简单文件传送协议TFTP
- 用于UDP
- 所占内存较小
远程终端协议TELNET
- 用户用TELNET就能通过TCP连接登录到远地的另一台主机(使用主机名或IP地址),这种服务是透明的, 因此TELNET也称为终端仿真协议
- 为适应硬件和OS的差异,TELNET定义了数据和命令在互联网中的传输格式,即网络虚拟终端NVT( Network Virtual Terminal ),数据在传输时(C To S , S To C)都被转为NVT格式
万维网WWW
- 万维网(World Wide Web)并非一个特殊的计算机网络,而是一个大规模的、联机式的信息储藏所。 万维网用链接的方法从互联网的一个站点访问另一个站点
- 万维网是个分布式的超媒体(hypermedia)系统,它是超文本(hypertext)系统的扩充
- 超文本: 包含指向其它文档的链接的text,即,超文本由多个信息源链接成
- 超媒体:超文本文档只能包含文本信息,超媒体文档还能包含其他表示方式的信息,如图形、声音...
- 万维网以CS模式工作, 浏览器就是在用户主机上的万维网客户程序。 万维网文档所驻留的主机则运行服务器程序,该主机也称为万维网服务器。在一个客户程序主窗口上显示出的万维网文档称为页面(page)
统一资源定位符URL
对资源的位置提供了抽象的识别方法,并用它来给资源定位
<协议>://<主机>:<端口>/<路径>
- 端口和路径可以省略。 省略“路径”,则URL指到主页
- 有些浏览器可以把"http://"和主机名最前面的"www"省略,当然浏览器会自动把它们添上
超文本传送协议HTTP
HTTP概述
- 面向事务的应用层协议,使用TCP
- HTTP本身是无连接的,即无需事先建立HTTP连接
- HTTP是无状态的,不记得曾经的客户,也不记得客户访问了多少次
- 默认端口
80 - 请求一个万维网文档所需的时间 = 该文档的传输时间 + 两倍RTT
- 一个RTT用于建立TCP连接,一个RTT用于请求和接收万维网文档
- TCP三报文握手的第三个报文段中的数据,就是客户对万维网文档的请求报文。 服务器收到HTTP请求报文后,就把所请求的文档作为响应报文返回给客户
- 为避免两倍RTT开销,HTTP/1.1使用了持续连接,它有两种工作方式:
- 非流水线模式( without pipeling ): 客户收到前一个响应后才能发出下一个请求. 因此,在TCP连接已建立后访问一次对象就要用去一个RTT
- 流水线模式( with pipelining ): 客户在收到HTTP的响应报文之前就能够接着发送新的请求报文
代理服务器
- 又称“万维网高速缓存
- client要向互联网上的server发送请求时,就先和proxy server建立TCP连接,并向其发送HTTP报文。若proxy server没找到所请求的对象,则由proxy server代表client与互联网上的源点服务器(origin server)建立TCP连接,并发送HTTP报文
HTTP报文结构
ref: https://blog.csdn.net/zephyr999/article/details/80055420
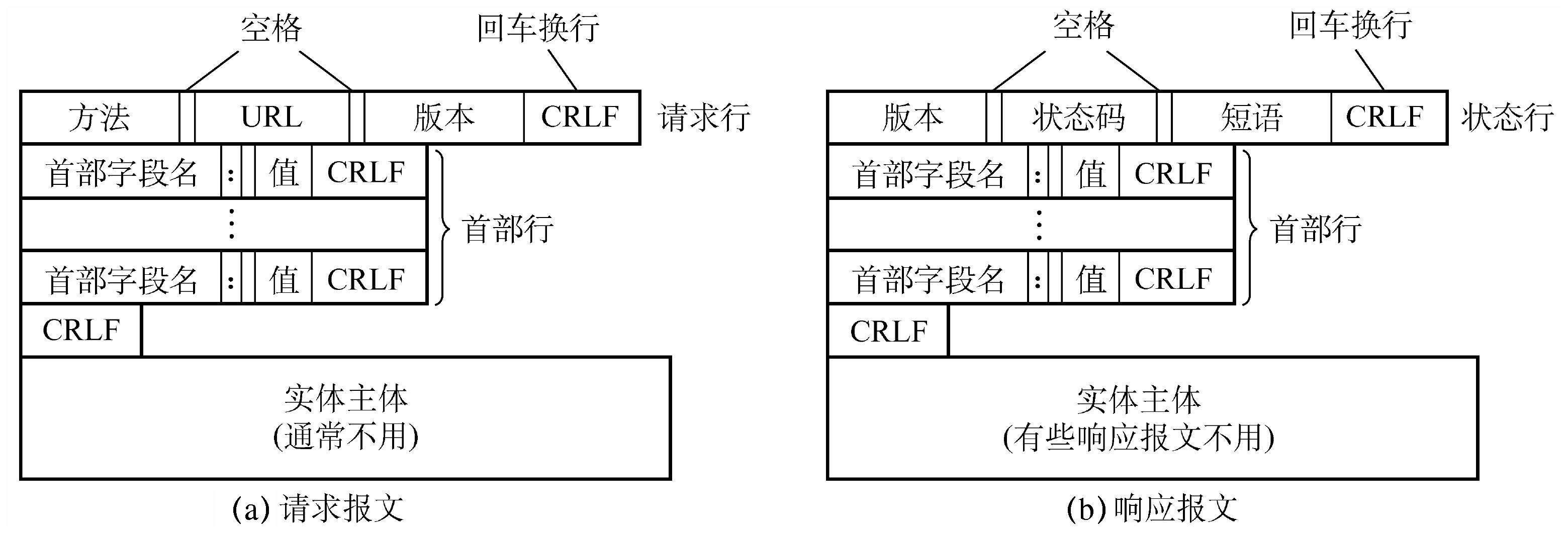
- 开始行
- 在请求报文中称为“请求行”
request line- 方法 + url + HTTP版本
- 在响应报文中称为“状态行”
status line- 服务器HTTP协议版本,响应状态码,状态码的文本描述
- 在请求报文中称为“请求行”
- 首部行(请求头部
header)- 首部行后空一行
- 实体主体
entity body- 该字段可能缺失
请求报文
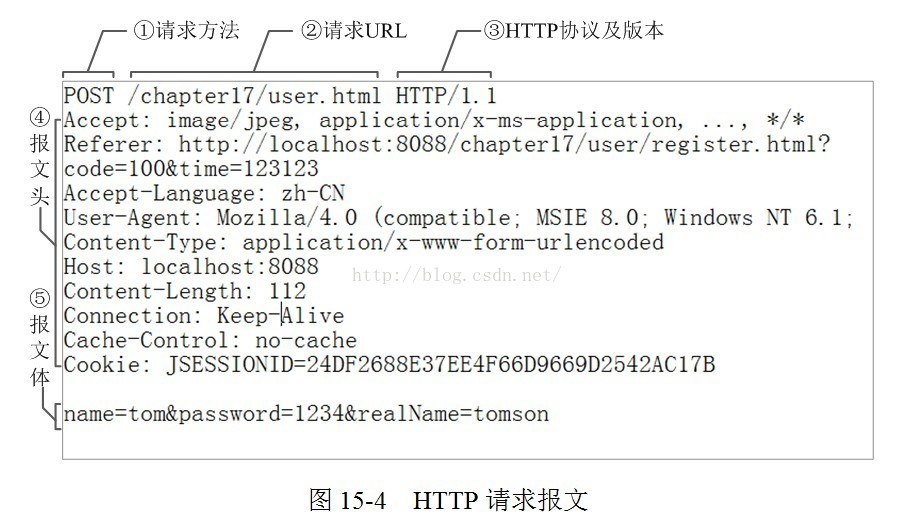
请求行由三部分组成:请求方法,请求URL(不包括域名),HTTP协议版本
请求方法比较多:GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT
最常用的是GET和POST
首部行(请求头部, 报文头):由 key/value 对组成,每行为一对,key 和 value 之间通过冒号(:)分割。请求头的作用主要用于通知服务端有关于客户端的请求信息
- User-Agent:生成请求的浏览器类型
- Accept:客户端可识别的响应内容类型列表;星号* 用于按范围将类型分组。/表示可接受全部类型,type/*表示可接受 type 类型的所有子类型。
- Accept-Language: 客户端可接受的自然语言
- Accept-Encoding: 客户端可接受的编码压缩格式
- Accept-Charset: 可接受的字符集
- Host: 请求的主机名,允许多个域名绑定同一 IP 地址
- connection:连接方式(close 或 keepalive)
- Cookie: 存储在客户端的扩展字段
- Content-Type:标识请求内容的类型
- Content-Length:标识请求内容的长度
请求体(报文体): 主要用于 POST 请求,与 POST 请求方法配套的请求头字段一般有 Content-Type和 Content-Length
常见的Content-Type:
Content-Type 解释 text/html html格式 text/plain 纯文本格式 text/css CSS格式 text/javascript js格式 image/gif gif图片格式 image/jpeg jpg图片格式 image/png png图片格式 application/x-www-form-urlencoded POST专用:普通的表单提交默认是通过这种方式。form表单数据被编码为key/value格式发送到服务器。 application/json POST专用:用来告诉服务端消息主体是序列化后的 JSON 字符串 text/xml POST专用:发送xml数据 multipart/form-data POST专用:下面讲解 - multipart/form-data
用以支持向服务器发送二进制数据,以便可以在 POST 请求中实现文件上传等功能
响应报文
由状态行、响应头、空行、响应内容四部分组成

- 状态行
状态行也由三部分组成:服务器HTTP协议版本,响应状态码,状态码的文本描述
格式:HTTP-Version Status-Code Reason-Phrase CRLF
比如:HTTP/1.1 200 OK
- 响应头:
- Location:服务器返回给客户端,用于重定向到新的位置
- Server: 包含服务器用来处理请求的软件信息及版本信息Vary:标识不可缓存的请求头列表
- Connection: 连接方式, close 是告诉服务端,断开连接,不用等待后续的请求了。 keep-alive 则是告诉服务端,在完成本次请求的响应后,保持连接
- Keep-Alive: 300,期望服务端保持连接多长时间(秒)
- 空行:(CR or LF ), 位于响应头和响应内容之间
- 响应内容:服务端返回给请求端的文本信息
状态码

1XX:服务器已接收了客户端的请求,客户端可以继续发送请求
2XX:服务器已成功接收到请求并进行处理
- 200:OK
- 202:No Content
- 206:Partial Content
3XX:服务器要求客户端重定向, 这表明浏览器需要执行某些特殊的处理以正确处理请求。
301:Moved Permanently
- 永久性重定向。 该状态码表示请求的资源已被分配了新的 URI, 以后应使用资源现在所指的 URI。
302:Found 临时性重定向。 该状态码表示请求的资源已被分配了新的 URI, 希望用户(本次) 能使用新的 URI 访问。
303:See Other, 表示由于请求对应的资源存在着另一个URI,应使用GET方法定向获取请求的资源。303状态码明确表示客户端应当采用GET方法获取资源,这点与302状态码有区别
- 当301、302、303响应状态码返回时,几乎所有的浏览器都会把POST改成GET,并删除请求报文内的主体,之后请求会自动再次发送
304:Not Modified, 请求的资源没有修改过, 304 虽然被划分在 3XX 类别中, 但是和重定向没有关系
307:Temporary Redirect, 与 302 Found 有着相同的含义,但浏览器不会把307从POST变成GET
4XX 客户端错误
- 400 Bad Request:请求报文中存在语法错误;
- 401 Unauthorized:该状态码表示发送的请求需要有通过 HTTP 认证(BASIC 认证、DIGEST 认证) 的认证信息。
- 403 Forbidden:请求的资源被服务器拒绝;
- 404 Not Found:服务器上无法找到资源;
5XX服务器错误
5XX的响应结果表明服务器本身发生错误
- 500 Internal Server Error:服务器端在执行请求时发生了错误
- 502 网关错误
- 503 Service Unavailable :服务器暂时处于超负载或正在进行停机维护, 现在无法处理请求
Cookie
为了避免HTTP无状态带来的不便,万维网站点可以用Cookie来跟踪用户
- Cookie: 在HTTP server 和 client间传递的状态信息
Cookie工作步骤:
当用户A浏览某个使用Cookie的网站时,该网站的服务器就为A产生一个唯一的识别码, 并以此为索引在后端数据库建立一个项目。接着在给A的HTTP响应报文中添加一个叫做
Set Cookie的首部行,其字段名为“Set Cookie”,值为识别码,如:Set-Cookie: 2134vsfva32ddf432
当A收到这个响应时,其浏览器就在它管理的特点Cookie文件中添加一行,其中包括这个识别码和server的主机名。当A继续浏览这个网站时,每发送一个HTTP请求报文,其浏览器就会从其Cookie文件中取出这个网站的识别码,放到HTTP请求报文的首部行中:
Set-Cookie: 2134vsfva32ddf432
于是,网站就能够跟踪用户2134vsfva32ddf432(用户A)
Web cache
- Web cache: 也称代理服务器( proxy server ), 被配置了 proxy server的浏览器的请求都会被定向到该proxy server
- proxy server会查询缓存,未命中则请求web server,将后者的内容缓存,并发给浏览器
- 递归式查询
- proxy server既是server(对于浏览器)也是clinet(对于web server)
- 应用:内容分发网络(
Content Distribution Network, CDN)
- proxy server会查询缓存,未命中则请求web server,将后者的内容缓存,并发给浏览器
Conditional GET
- proxy cache带来“陈旧缓存”问题,为此proxy cache可以向web server发送
Conditional GET- 具体而言, server每次都会向 proxy server发送
Last-Modified-Since:date字段。 一段时间后,当用户请求代理服务器查询该资源时, proxy server会对web server发送If-Modified-Since: date 字段- 如果未修改,则只返回一个响应报文,不用返回对象( 状态码
304 Not Modified)
- 如果未修改,则只返回一个响应报文,不用返回对象( 状态码
- 具体而言, server每次都会向 proxy server发送
万维网的文档
静态文档
- 文档放在服务器中,在用户浏览过程中,内容不会改变
动态文档
- 文档是在client访问server时才由应用程序动态创建
- 当请求到达时,server要运行另一个应用程序。server把client发来的数据交给这个进程,且server能解释这个进程的输出,以及这个输出结果该如何使用,这就需要通用网关接口CGI( Common Gateway Interface ), 它既指CGI标准,也指程序
活动文档
- 动态文档一旦生成,内容就固定了,无法及时刷新屏幕。为了屏幕的及时更新,有两种技术:
- 服务器推送(server push): 将所有工作交给服务器,服务器不断运行与动态文档相关联的应用程序,定时更新信息,并发送更新过的文档
- server要为每个client维持一个不释放的TCP连接
- 活动文档(active document): 所有工作交给浏览器端。服务器返回一个程序,它在浏览器端运行
- Java applet
- 服务器推送(server push): 将所有工作交给服务器,服务器不断运行与动态文档相关联的应用程序,定时更新信息,并发送更新过的文档
- 服务器端的活动文档内容是不变的,从传送的角度看,两种技术都把活动文档看成静态文档
万维网的信息检索系统
搜索引擎: 万维网中用来进行搜索的工具。 分为全文检索和分类目录两种。现在还出现了垂直搜索引擎和元搜索引擎,
全文检索:爬虫,建立索引,从已建立的索引数据库中查询
分类目录:不主动采集网站的信息,由网站向搜索引擎主动提交信息,经人工审核编辑后,输入到分类目录的数据库中。 查询时不需要关键词,只需按照分类。
垂直搜索引擎:也是关键词搜索,但只针对某一领域、某一人群等
元搜索引擎:把请求发给多个搜索引擎,再把结果集中处理
电子邮件
电子邮件系统三要素: 用户代理、邮件服务器、邮件发送协议(SMTP)和邮件读取协议(POP3)
- 用户代理(UA):就是电子邮件客户端软件
- 邮件发送协议:用于UA向邮件服务器发送邮件或在邮件服务器之间发送邮件
- 邮件读取协议: UA从邮件服务器读取邮件
- SMTP, POP3, IMAP都用TCP
用户在浏览器中浏览信息需要HTTP. 因此浏览器和邮件服务器之间传送邮件时,用HTTP. 而各邮件服务器之间传送邮件时,仍然使用SMTP
Email发送和接收步骤:
- 用户发送邮件,把工作全部交给UA. 后者把邮件用SMTP协议发给发送方邮件服务器
- 此时UA充当SMTP客户,发送方邮件服务器充当SMTP服务器
- SMTP服务器(即发送方邮件服务器)收到邮件后,将其暂放在邮件缓存队列中
- 发送方邮件服务器与接收方邮件服务器建立TCP连接(不会中转),然后依次把邮件缓存队列的邮件发出去
- 接收方邮件服务器中的SMTP服务器进程收到邮件后,把邮件放到收件人的信箱中
- 收件人打算收信时,运行UA,使用POP3(or IMAP)协议拉取邮件
- 有些“”特快专递“服务能够让UA直接用SMTP发给接收方邮件服务器( 不用发给发送方邮件服务器了 )
- 用户发送邮件,把工作全部交给UA. 后者把邮件用SMTP协议发给发送方邮件服务器
Email由信封和内容组成
信封上最重要的就是收件人的地址,电子邮件地址格式:
用户名 @ 邮件服务器的域名
内容分为首部和主体,后者用户自己撰写
- 首部包括一些关键字,最重要的有
- To: 收件人的邮件地址
- Subject:主题
- Cc:抄送,即留下一个复写副本
- 首部包括一些关键字,最重要的有
简单邮件传送协议SMTP
- 不使用中间邮件服务器
- 本用于传输ASCII码而不是二进制文件,后来虽然有了MIME可以传输二进制数据,但效率不高,为此有了Extended SMTP
邮件读取协议POP3
- POP3: UA必须允许POP3 client , 而收件人所连接的ISP的邮件服务器中则运行POP3 server,当然,它还要运行SMTP server以收信
- POP3 server需要用户输入鉴别信息( 用户名和口令 )
- 流程: 特许
authorization,事务处理, 更新- 特许:UA以明文发送用户名和口令
- 主要命令:
user <username>pass <passwd>( 现在一般要输入授权码而不是密码 )
- 主要命令:
- 事务处理:UA可以对邮箱做一些操作,如
list,retr,dele,quitquit仅仅给邮件打上删除标记,并没有删除邮件
- 更新:客户发出
quit之后,结束该pop3 session,并删除那些被标记为删除的报文
- 特许:UA以明文发送用户名和口令
- POP3用户将邮件从服务器下载到本地
1 | telnet pop.qq.com 110 //qq官网给的端口是995,但我用995是无法访问的,不知道为什么 |
邮件读取协议IMAP
- IMAP:用户在自己的计算机上就可以操纵邮件服务器上的邮箱,就像在本地操纵一样
- 允许UA只获取邮件的一部分
基于 web的电子邮件
- UA就是浏览器
通用互联网邮件扩充MIME
- 新增了5个首部
- 定义了许多邮件内容的格式,对多媒体邮件的表示方法进行了标准化
- 定义了传送编码
动态主机配置协议DHCP
- DHCP步骤:
- 需要IP地址的主机在启动时就广播发送DHCP发现报文(DHCPDISCOVER)
- 广播是因为此时不知道DHCP服务器在哪
- 目的地址是全1
- 源地址是全0,因为此时主机没有IP地址
- 本地网络上所有主机都能收到这个报文,但只有DHCP服务器才能对它回答。(返回报文称为”提供报文“)
- DHCP服务器先在其数据库中查找该计算机的配置信息,若找到,则返回找到的信息;若没找到,则从其地址池(address pool)中取一个地址分配给主机
- 需要IP地址的主机在启动时就广播发送DHCP发现报文(DHCPDISCOVER)
- 为每个网络都设置DHCP服务器代价太高,解决方案是每个网络至少有一个DHCP中继代理, 它配置了DHCP服务器的IP地址等信息
- 当中继代理收到主机的DHCP广播发现报文后,就以单播方式向DHCP服务器转发此报文,收到提供报文后,中继代理再把此提供报文发给主机
- DHCP分配的地址是暂时的,称为“租用期”
- DHCO报文采用UDP
希望我更新的话,请(以各种手段)催更我哦q(≧▽≦q)